|
|
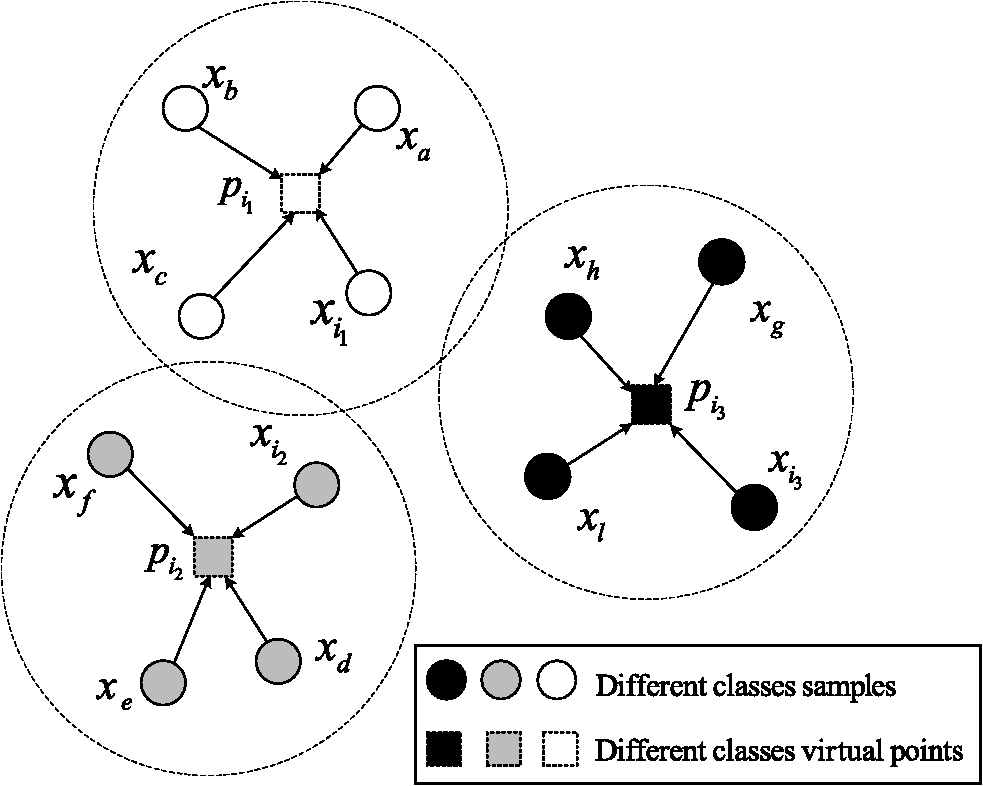
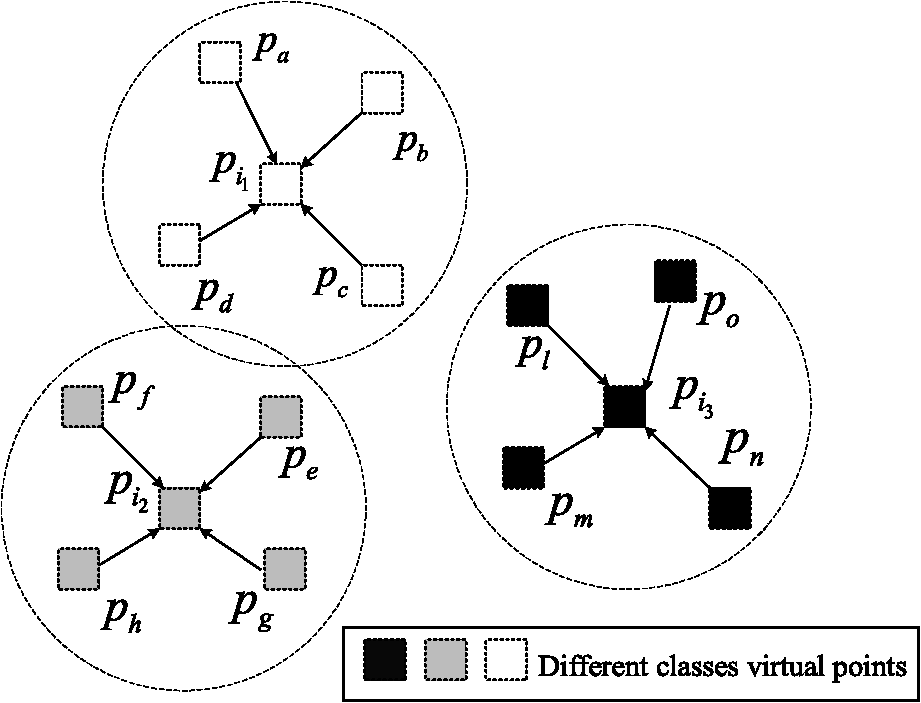
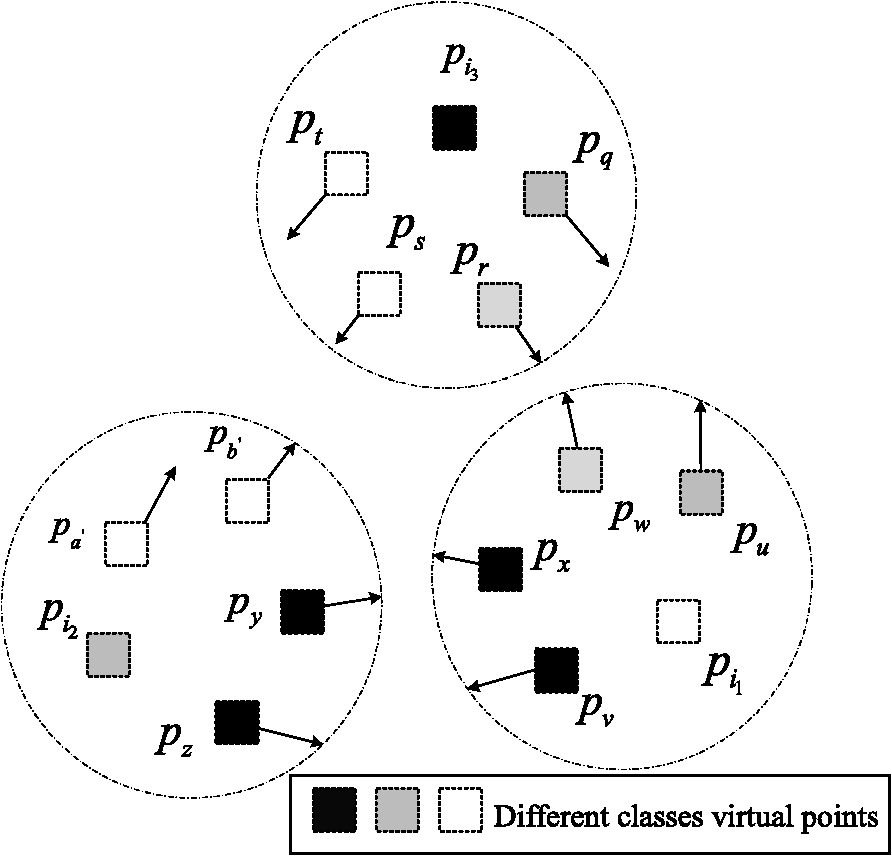
1.IntroductionFeature extraction is one of the key steps of synthetic aperture radar automatic target recognition (SAR ATR), which can reduce the dimensions of SAR images and extract the effective discriminating feature. Generally, feature extraction methods are placed into two categories: linear and nonlinear. Classical linear methods, such as principal component analysis (PCA),1 and linear discriminant analysis (LDA),2 are based on the global linear structure of data. The best recognition rates employing PCA and LDA are higher than 80%, as shown by experiments based on the Moving and Stationary Target Acquisition and Recognition (MSTAR) database.3 With the development of the support vector machine,4 nonlinear feature extraction methods based on kernel tricks, such as kernel principal component analysis5 (KPCA) and kernel linear discriminant analysis (KLDA),6 have been widely applied in SAR ATR. By introducing the kernel function, those methods can solve the linearly inseparable problem of sample data to some extent. However, a main shortcoming of the kernel tricks is that the recognition performance depends on the selection of kernel settings. Another novel nonlinear method, manifold learning,7 has been proposed on the premise that high-dimensional images lie on or near a low-dimensional manifold embedded in the high-dimensional space. For the purpose of seeking a low-dimensional manifold embedded in the high-dimensional data space, various manifold learning algorithms have been proposed, such as isometric feature mapping,8 locally linear embedding9 (LLE), Laplacian eigenmaps (LE),10 locality preserving projections (LPP),11 neighborhood preserving embedding (NPE),12 and orthogonal neighborhood preserving projections (ONPP).13 In Cai et al.,14 the LPP algorithm was introduced into inverse synthetic aperture radar target recognition, and the classification results were better than those obtained from PCA and LDA. However, LPP ignored the class information of the samples and discarded the target information from SAR images.15 The main goals of the manifold learning algorithms above are to preserve localities or similar rankings, and those methods are more appropriate for retrieval or clustering, rather than classification. By integrating the neighborhood information and class relations of samples, some supervised manifold learning methods have been proposed, including local discriminant embedding16 (LDE). Bryant17 demonstrated the application of signature manifold methods on SAR images, which has achieved considerable detection and classification results. In Venkataraman et al.,18 capturing the inter-class and intra-class variability of target shapes, coupled view and identity manifolds for shape representation was applied to target tracking and recognition. This method produced an effective classification performance. Manifold learning algorithms such as LDE only structure the adjacent graphs using samples in their neighborhoods; they ignore the spatial relationships between neighborhoods, which will restrict the classification performance. To solve the aforementioned problems, a new feature extraction method, neighborhood virtual points discriminant embedding (NVPDE), is proposed. By introducing the virtual point in every sample’s neighborhood, relations between the samples in the neighborhood taken into account, and the spatial relationships of the neighborhoods are established. When embedded into the low-dimensional feature space, the neighborhood virtual points with the same class label, as well as every sample and its neighborhood virtual point, get together, whereas the neighborhood virtual points from different classes separate from each other. In this way, the recognition performance can be improved. This paper is organized as follows. Section 2 details the proposed algorithm framework: samples gathered in the neighborhood, neighborhood virtual point discriminant, and objective function are detailed in Secs. 2.1 to 2.3, respectively. Section 3 shows experimental results, and Sec. 4 concludes this paper. 2.Neighborhood Virtual Points Discriminant EmbeddingLet be a manifold embedded in . The training dataset is , and corresponding data class labels are , where denotes the amount of training data, and denotes the class number of training data. Any subset of data points that belong to the same class is assumed to lie on a submanifold of . In NVPDE, the virtual points are introduced into the samples’ within-class neighborhoods, and then an embedding based on linear projection is constructed: , . Via embedding, each sample in the low-dimensional space moves toward its neighborhood virtual point , while the virtual points with the same class label get together, and the virtual points from different classes separate from each other. 2.1.Samples Gathered in NeighborhoodWe calculate the within-class neighborhood for each sample and select the neighborhood virtual point from each neighborhood . Here, indicates the set of the nearest neighbors of the sample in the same class, , , and is the virtual points selecting function. Here, we select the geometric center of the neighborhood as the neighborhood virtual point: , , . The sample’s within-neighborhood objective function is defined as where is the sample’s within-neighborhood affinity weight matrix, which is defined as demonstrates the spatial relationships between the samples and their respective neighborhood virtual points: The smaller the value of , the closer the samples are to their neighborhood virtual points. The explanation of the process of samples gathered in neighborhood is shown in Fig. 1, which shows that each sample will move toward its neighborhood virtual point.Referring to Eq. (1), we can infer that where , , and . Let , where and . Thus, Let . Thus,2.2.Neighborhood Virtual Point DiscriminantBecause each neighborhood virtual point is a linear combination of the samples in the neighborhood and , the neighborhood virtual points are essentially high-dimensional image data, as well. Therefore, they should lie on or near the low-dimensional manifold embedded in the high-dimensional space. According to the samples’ class labels, the class labels corresponding to the neighborhood virtual points are . Any subset of neighborhood virtual points that belong to the same class is assumed to lie on a submanifold of . The within-class neighborhood virtual point objective function is defined as where is the neighborhood virtual point affinity weight matrix, which is defined as where indicates the set of the nearest neighbors of the neighborhood virtual point in the same class.demonstrates the spatial relationships between the neighborhood virtual points in the same class: The smaller the value of , the closer the neighborhood virtual points are to each other. The explanation of the process of neighborhood virtual point discriminant in the same class is shown in Fig. 2, which shows that the virtual points in the same class will get together. The between-class neighborhood virtual point objective function is defined as where is the neighborhood virtual point penalty weight matrix, which is defined as where indicates the set of the nearest neighbors of the neighborhood virtual point from different classes.demonstrates the spatial relationships between the neighborhood virtual points from different classes: The larger the value of , the further the neighborhood virtual points are from each other. The explanation of the process of neighborhood virtual point discriminant from different classes is shown in Fig. 3, which shows that the virtual points from different classes will separate from each other. Referring to Eq. (7), we can infer that where , , , and . Let , where and . Thus, where .Referring to Eq. (9), we can infer that where , , , and . Let , where and . Thus, where .2.3.Objective FunctionFor the purpose of classification, we expect that and have small values, while has a large value, so that each sample in the low-dimensional space will move toward its neighborhood virtual point, while the virtual points in the same class get together, and the virtual points from different classes separate from each other. Therefore, the samples in the same class will get close, whereas the samples of different classes will separate from each other in low-dimensional space. Let . Referring to Eqs. (6) and (12), we can infer that Consequently, according to Eqs. (14) and (15) and Fisher’s criterion,19 the objective function of NVPDE can be formulated as The columns of the optimal are the generalized eigenvectors corresponding to the largest eigenvalues in The NVPDE algorithm procedures are formally stated as follows: Concerning the computational complexity of the proposed algorithm, we note that the complexity of searching nearest neighbors for all the samples and neighborhood virtual points is . The complexity of calculating the elements of weight matrices is . The complexity of computing the matrices and is , and the complexity of solving the generalized eigenvalue decomposition problem is . In most cases, the number of training samples is less than the dimension of the training sample . Therefore, like most other feature extraction methods, the computational bottleneck of NVPDE is solving the generalized eigenvalue problem, whose computational complexity is . 3.Experimental ResultsIn this section, the MSTAR20 and AT&T face databases are utilized to evaluate the proposed algorithm. The MSTAR dataset consists of X-band original SAR images ( pixels) with a resolution of one foot by one foot. The target images are three types of military vehicles. Each object includes images covering the full aspect range of 0 deg to 360 deg. In this work, the training dataset contains SAR images at a depression angle of 17 deg, and the testing dataset contains images at a depression angle of 15 deg. Table 1 lists the type and number of each object. Table 1The training and testing samples in experiments.
We mainly make use of the targets in the MSTAR SAR images to evaluate the performance of the proposed algorithm. The original SAR image dataset has been preprocessed21 to extract the target areas of SAR images before feature extraction. The steps of SAR image preprocessing are as follows:
The optical images and the corresponding SAR images of the three targets in the MSTAR dataset are shown in Figs. 4 and 5. In Fig. 6, it is shown that the binary mask matrices of the targets are obtained after two-parameter CFAR and geometric clustering conducted in the SAR images. Figure 7 indicates that the target areas of SAR images are extracted, and the image registration centered on the centroid is operated. The gray enhancement and energy normalization preprocessing are executed as shown in Fig. 8. The AT&T face database25 contains images from 40 individuals, each providing 10 different images. For some subjects, the images were taken at different times, varying the lighting, facial expressions, and facial details. All images are grayscale. For each individual, four images are randomly selected for training, and the rest are used for testing. Thus, we get 160 training samples and 240 testing samples for this experiment. The experiment includes four parts. The theoretical approach of the proposed algorithm will be validated using the SAR image dataset in part 1. In part 2, we compare our algorithm with five other methods (PCA, LDA, KPCA, KLDA, and LDE) to evaluate the recognition performance for SAR images. We also illustrate the classification results by a two-dimensional data visualization to evaluate the performance of NVPDE. In part 3, we evaluate and discuss the influences of the relevant neighbor parameters variation for the proposed algorithm in SAR ATR. The recognition results for the face image database are demonstrated in part 4. 3.1.Part 13.1.1.Experimental stepsBecause of the local Euclidean principle in manifold,9 samples and virtual points have a nearly linear distribution in the neighborhoods. Therefore, we utilize the scatter26 to measure the spatial relationships among the data points in their neighborhoods statistically.
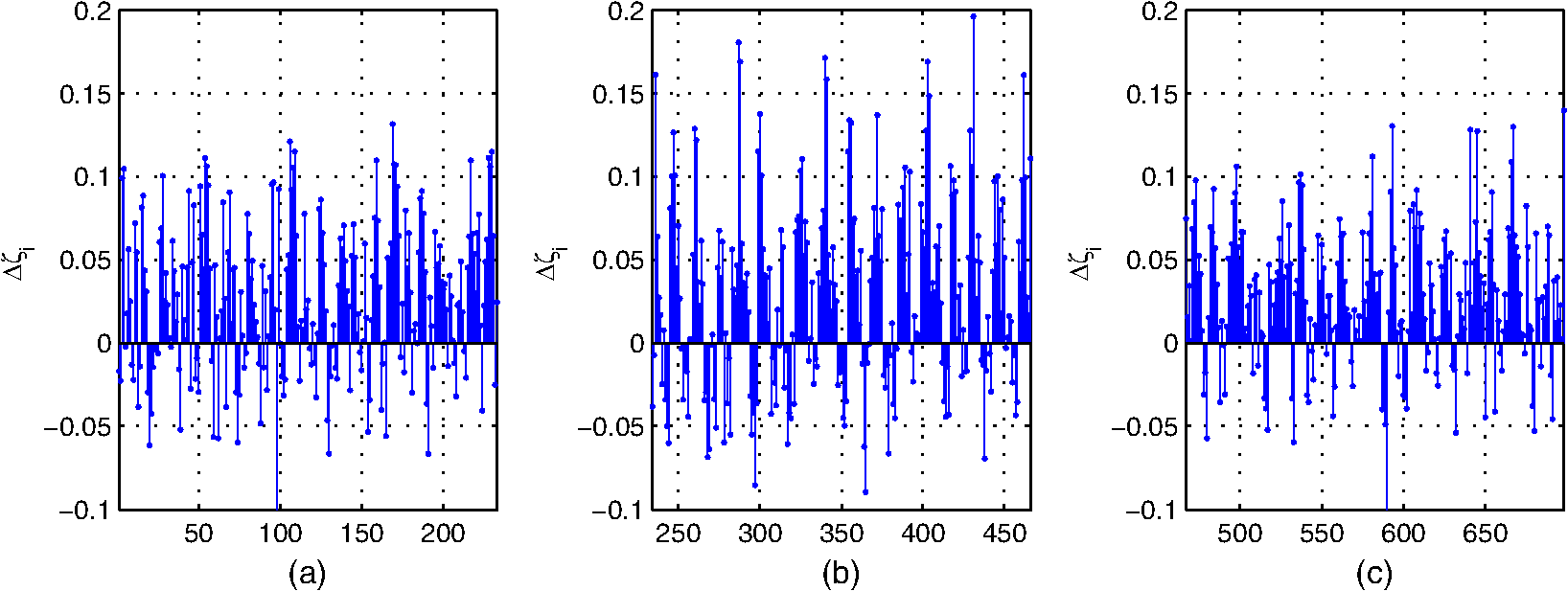
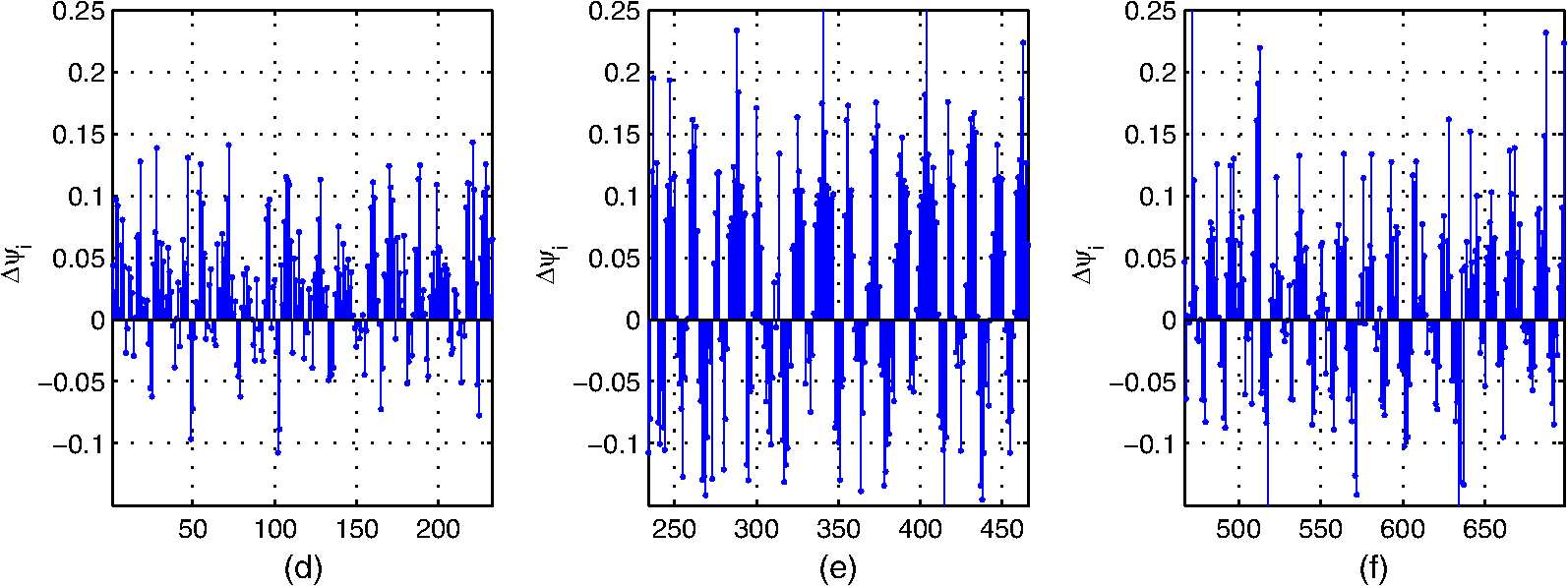
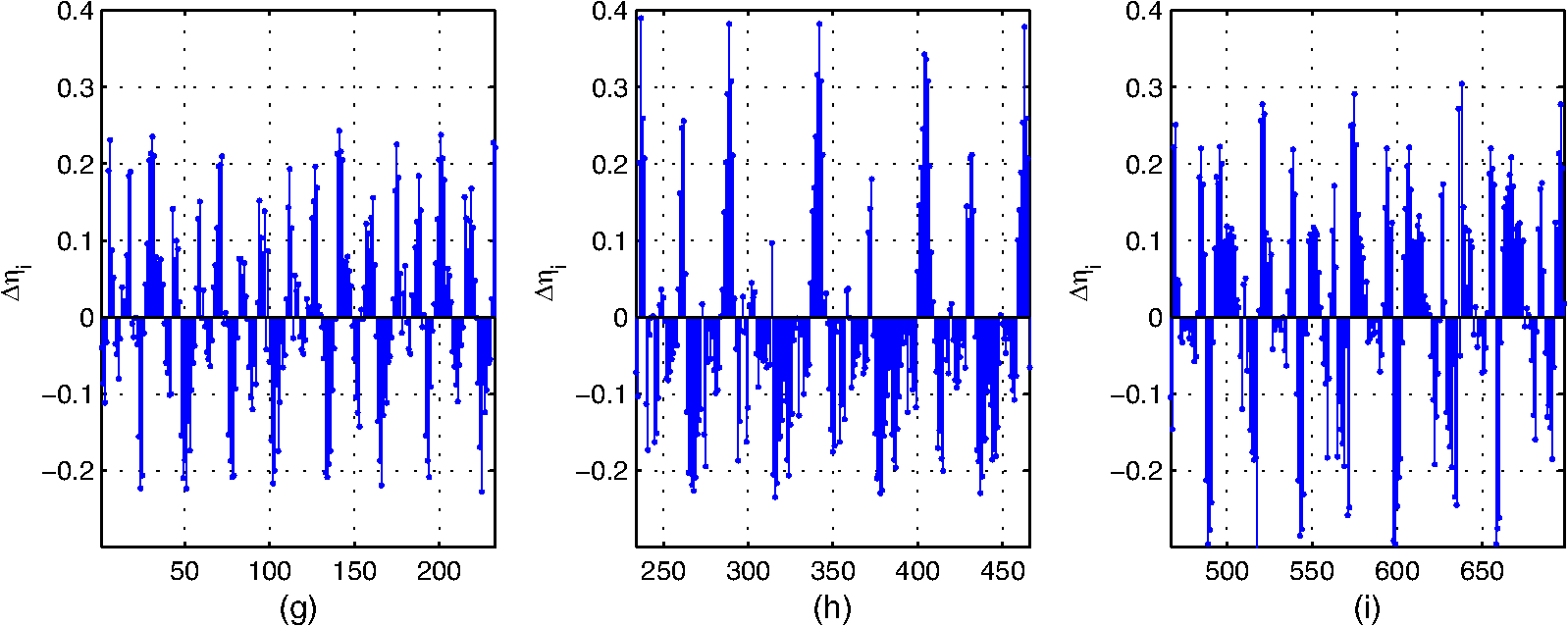
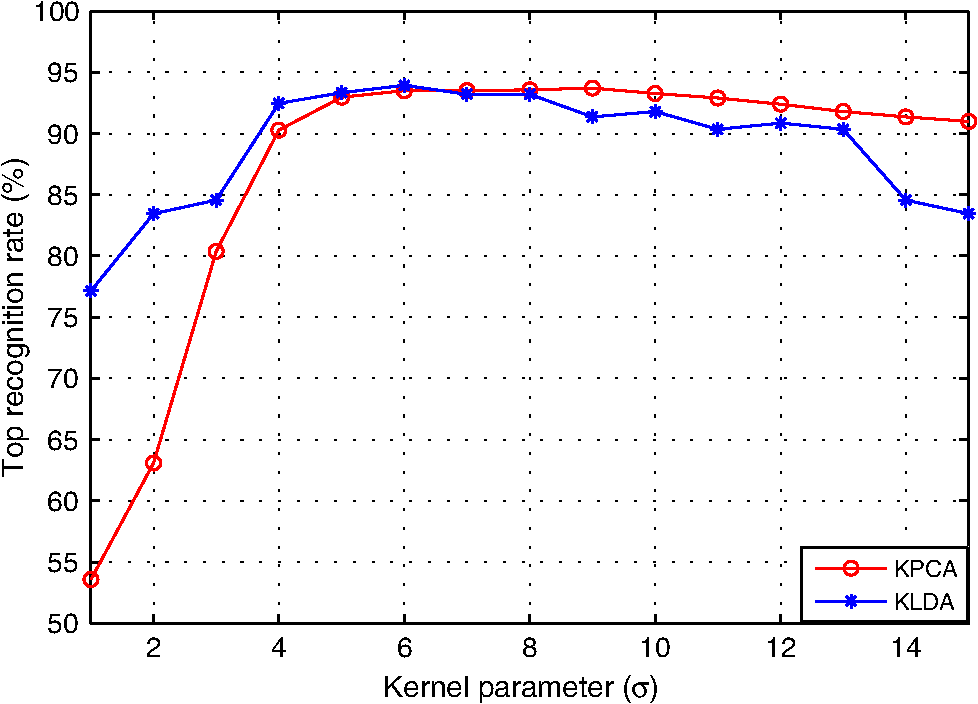
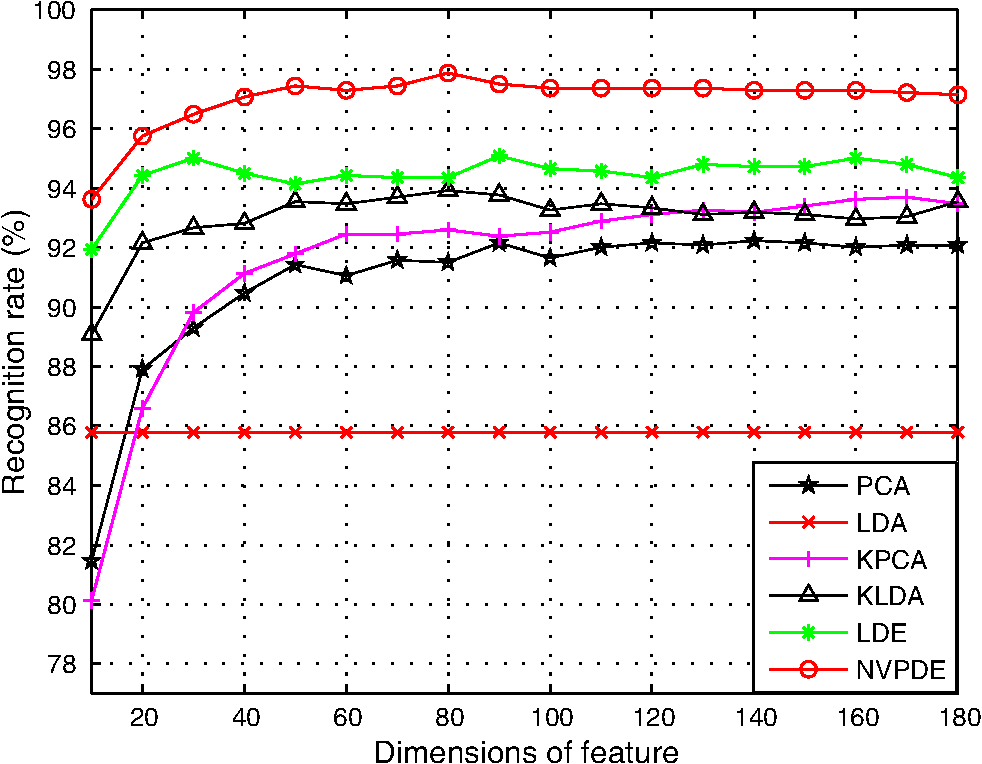
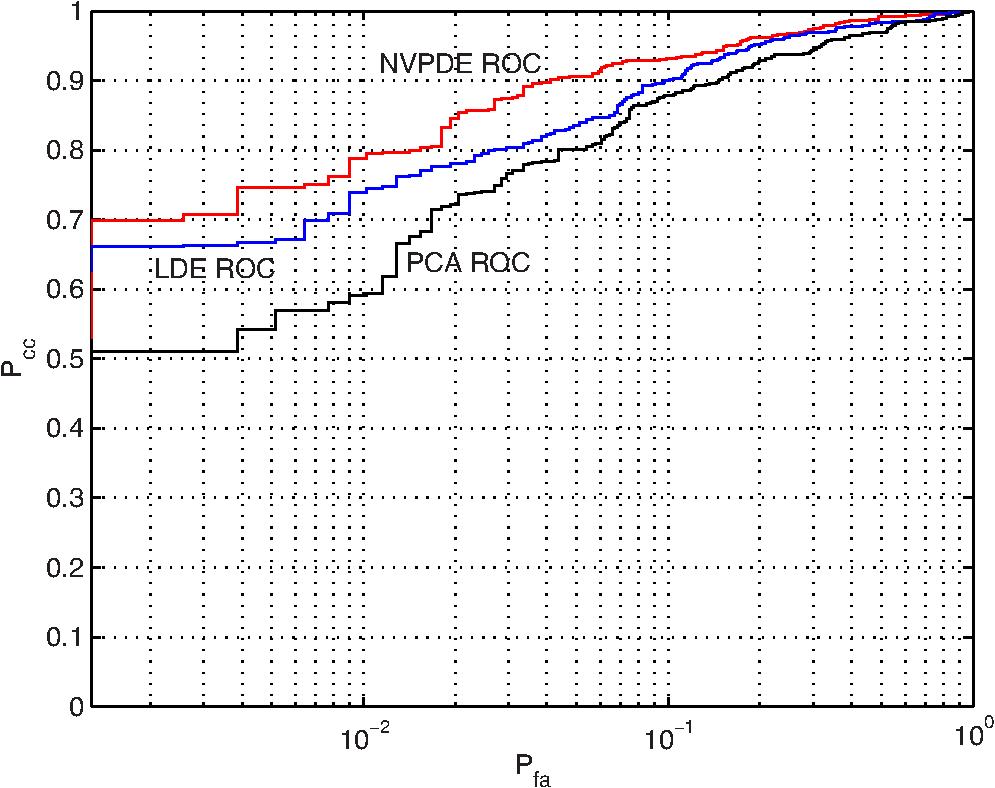
3.1.2.Experimental results and discussionsWe make some statistics according to the elements of , , and . The proportion corresponding to the condition is 71.06%. The proportion corresponding to the condition is 61.32%, and the proportion corresponding to the condition is 55.59%. According to Figs. 9 and 10 and the statistical results, it can be seen that most of the samples’ within-neighborhood scatter variations and the virtual points’ within-class neighborhood scatter variations are positive. This indicates that the samples move toward their neighborhood virtual points, and the virtual points in the same class get together by the embedding of the proposed method. From Fig. 11 and the statistical results, it can be seen that more than half of the virtual points’ between-class neighborhood scatter variations are negative. This demonstrates that the NVPDE algorithm can keep the virtual points from different classes far away from each other in the low-dimensional space effectively. 3.2.Part 23.2.1.Experimental stepsIn this experiment, PCA, LDA, KPCA, KLDA, LDE, and NVPDE are utilized to extract features of the experimental SAR image dataset. The value of neighbor parameters are and in LDE and , , and in NVPDE. The nearest neighbor classifier27 (NNC) is utilized for the final classification. The kernel function of KPCA and KLDA is the Gaussian kernel . As mentioned above, the recognition performance of the kernel method depends on the kernel settings, and the selection of the kernel settings is empirical in practice. We change the kernel parameter gradually and get the corresponding top recognition rates. Then we evaluate the best kernel parameter. Figure 12 shows that plots of top recognition rate versus the different values of kernel parameters using KPCA and KLDA. From this, we can see that the kernel parameters for KPCA and for KLDA are the best selections. 3.2.2.Experimental results and discussionsFigure 13 shows plots of recognition rate versus dimensions of the feature vectors by PCA, LDA, KPCA, KLDA, LDE, and NVPDE. The maximal feature dimension based on LDA is less than the number of class .28 Therefore, the recognition rate of LDA is the performance with two feature dimensions. From Fig. 13, we can see that PCA and LDA have relatively low recognition rates. For the high-dimensional SAR image dataset, the manifold structure corresponds more to spatial distribution. However, the classical linear feature extraction methods, such as PCA and LDA, are all based on the global linear structure of a dataset. This limits the recognition performance of those two methods. Figure 13 demonstrates that the recognition rates of KPCA and KLDA are similar but are significantly improved over PCA and LDA. LDE performs better than KPCA and KLDA. The NVPDE algorithm performs far better than the other methods. The linearly inseparable problem can be transformed into a linearly separable one in a higher-dimensional space by kernel tricks, so that the linearly inseparable problem can be solved by KPCA and KLDA to some extent. However, the recognition performance depends on the selection of kernel functions, which is the main drawback of kernel tricks. Based on manifold learning theory, LDE incorporates the class relations of samples, which can discover the low-dimensional essential structure from a high-dimensional SAR image dataset. However, this method is based only on establishing relations between samples; it ignores the spatial relationships between neighborhoods, which will restrict the recognition performance. By introducing the neighborhood virtual point into every sample’s neighborhood in the NVPDE algorithm, the relations between the samples and their neighborhood virtual point are taken into account, and the spatial relationships of the neighborhood virtual points are established, by which the relations between neighborhoods are formed indirectly. Therefore, the algorithm is able to find out more discriminating information from the neighborhoods, and the recognition performance is far superior to LDE. In order to evaluate the classification performance of the proposed feature extraction method systematically, we investigate the ROC of the proposed method,29 and two typical feature extraction methods (PCA and LDE) were conducted for a comparison. Figure 14 shows the ROC of three feature extraction methods using NNC, and the false alarm probability axis is logarithmic. From Fig. 14, it can be seen that:
The top recognition rate and the corresponding dimensions by various algorithms are shown in Table 2, and we can see that our proposed algorithm outperforms the other methods. Table 2Best recognition performance by various algorithms.
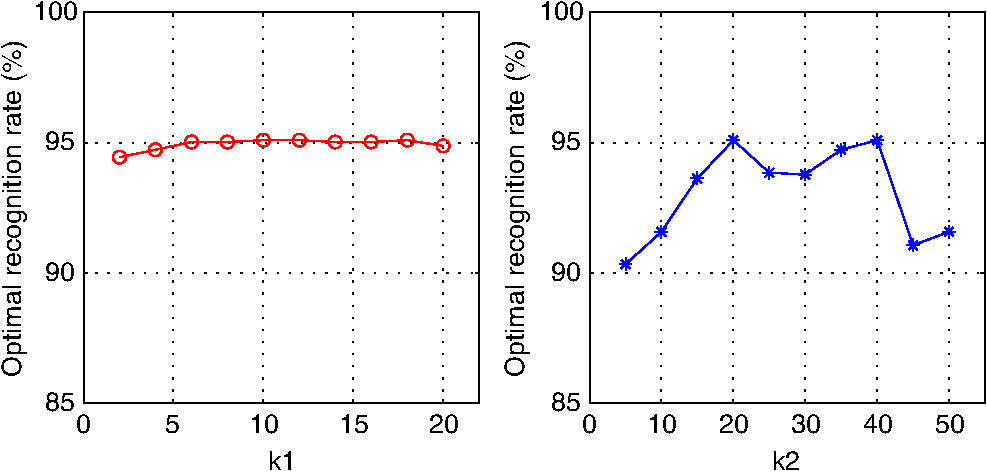
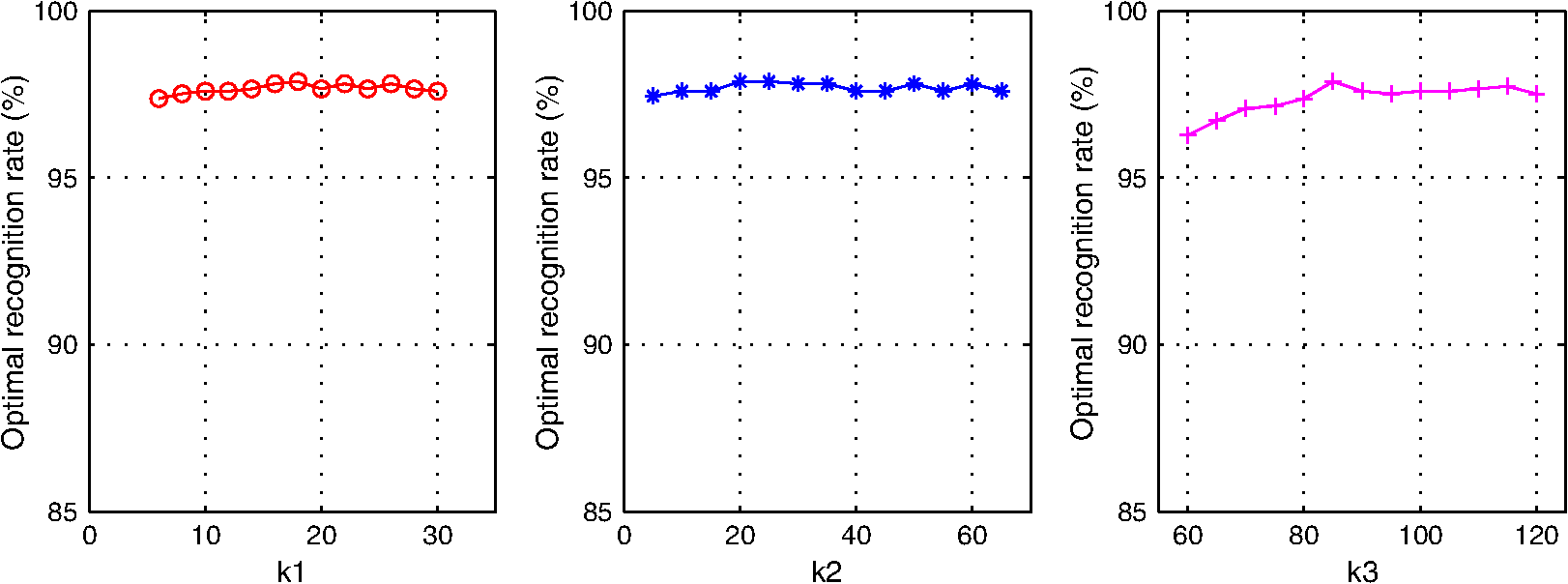
The training samples of the SAR images are embedded into two-dimensional Euclidean space by NVPDE, LDE, and PCA to illustrate the classification results with a 2-D data visualization example. Figure 15 shows the distributions of three class samples after being embedded in two-dimensional Euclidean space by NVPDE, LDE, and PCA. The plus symbol represents the first-class samples in the embedding space, while the represents the second-class samples, and the asterisk represents the third-class samples. Fig. 15Distributions of three class samples after being embedded in two-dimensional Euclidean space by (a) NVPDE, (b) LDE, and (c) PCA. 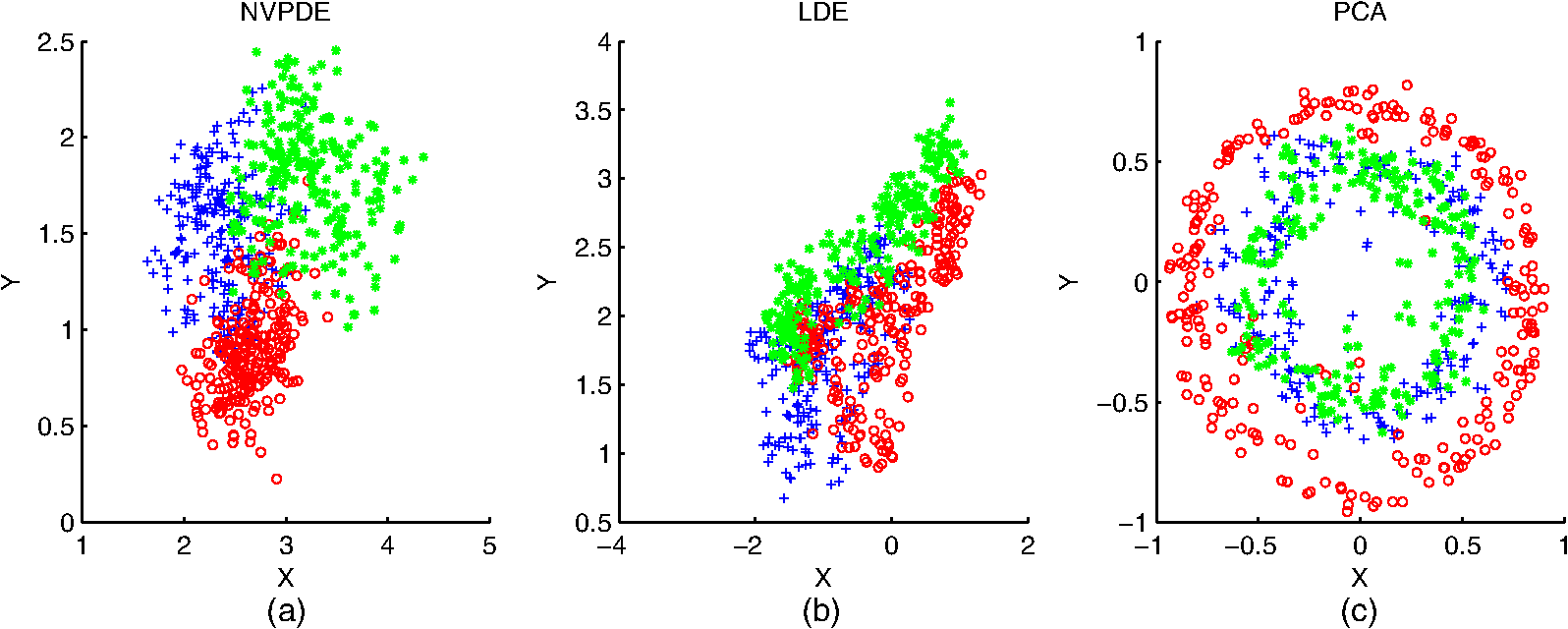 The experimental results show that samples in the same class do not get evidently close in the embedding space by PCA. After being embedded by LDE, the samples with the same class label get close to some extent, but most samples from different classes overlap with each other, which will restrict the recognition rate. By introducing the neighborhood virtual point in NVPDE, the relationships between neighborhoods are established indirectly, and more discriminating information can be found out. Hence the samples with the same class label get close, and samples from different classes separate from each other in the embedding space, as shown in Fig. 15. 3.3.Part 33.3.1.Experimental stepsIn this part, LDE and NVPDE will be utilized to extract features of the experimental dataset with various neighbor parameter values. The aim is to evaluate the stability of the proposed algorithm. We set and in LDE and , , and in NVPDE as the benchmark parameter settings. We then change one of the neighbor parameters gradually while keeping other parameters constant, and we record the corresponding top recognition rates of the two feature extraction methods. 3.3.2.Experimental results and discussionsFigures 16 and 17 show the plots of top recognition rates versus the different values of neighbor parameters using LDE and NVPDE. From these figures, we can see that:
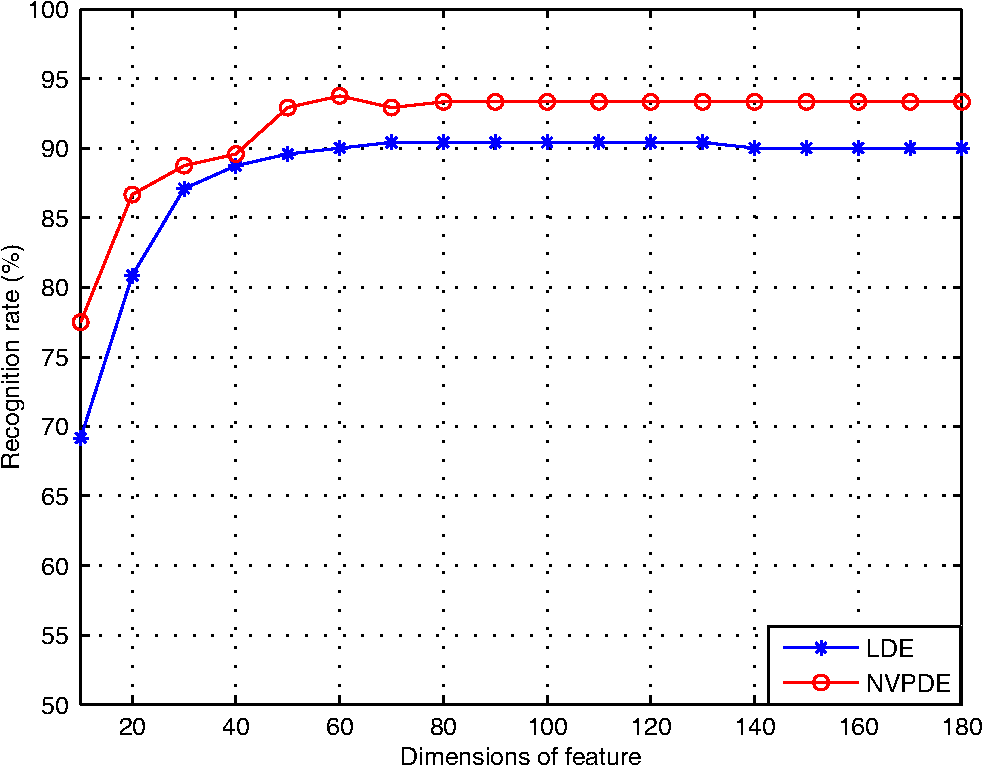
Because the curvature and density may vary over the manifold,30 as an open problem,31 the values of neighbor parameters are likely to influence the result of recognition as in LDE. In the NVPDE algorithm, the neighborhood virtual point of each sample is computed. In this way, the mean of each neighborhood is calculated, which is able to smooth the neighborhood of each sample and weaken the influence of neighbor parameters on recognition performance. Therefore, the selection of neighbor parameters has a very small effect on the classification results of our proposed method. 3.4.Part 43.4.1.Experimental stepsIn this part, we take advantage of the AT&T face database to examine the applicability of the proposed method in optical image recognition. LDE and NVPDE are utilized to extract features of the experimental AT&T dataset. The values of the neighbor parameters are and in LDE and , , and in NVPDE. NNC is used for the final classification. 3.4.2.Experimental results and discussionsFigure 18 shows plots of recognition rates versus the dimensions of the feature vectors by LDE and NVPDE. In Fig. 18, the best recognition rate is 90.42% with the corresponding feature dimension 70 for LDE, while the top recognition rate can get to 93.75% with the corresponding feature dimension 60 in NVPDE. This means that the recognition performance of the proposed method outperforms LDE for the AT&T face database. Therefore, the experimental results indicate that the NVPDE method can achieve a satisfactory recognition performance in optical image recognition, as well. 4.ConclusionFor the issue of feature extraction from high-dimensional SAR images, it is important to establish relationships between samples’ neighborhoods, which will uncover much more discriminating information. In this paper, a new approach to feature extraction was proposed, in which the neighborhood virtual points are employed and the relationships between neighborhoods are taken into account sufficiently. Through this method, classification is better conducted in feature space, and the recognition performance is improved. The experimental results based on the MSTAR dataset demonstrate the effectiveness of our method. AcknowledgmentsThis research was supported by the National Natural Science Foundation of China (No. 61201272). ReferencesM. TurkA. Pentland,
“Eigenfaces for recognition,”
J. Cognit. Neurosci., 3
(1), 71
–86
(1991). http://dx.doi.org/10.1162/jocn.1991.3.1.71 JCONEO Google Scholar
P. N. Belhumeuret al.,
“Eigenfaces vs. Fisherfaces: recognition using class specific linear projection,”
IEEE Trans. Pattern Anal. Mach. Intell., 19
(7), 711
–720
(1997). http://dx.doi.org/10.1109/34.598228 ITPIDJ 0162-8828 Google Scholar
A. K. Mishra,
“Validation of PCA and LDA for SAR ATR,”
in TENCON 2008—2008 IEEE Region 10 Conf.,
1
–6
(2008). Google Scholar
Q. ZhaoJ. C. Principe,
“Support vector machines for SAR automatic target recognition,”
IEEE Trans. Aerosp. Electron. Syst., 37
(2), 643
–654
(2001). http://dx.doi.org/10.1109/7.937475 IEARAX 0018-9251 Google Scholar
B. Scholkopfet al.,
“Kernel principal component analysis,”
Advances in Kernel Methods-Support Vector Learning, 327
–352 MIT Press, Cambridge, Massachusetts
(1999). Google Scholar
S. Mikaet al.,
“Fisher discriminant analysis with kernels,”
in Proc. 1999 IEEE Signal Processing Society Workshop,
41
–48
(1999). Google Scholar
H. S. Seunget al.,
“The manifold ways of perception,”
Science, 290
(5500), 2268
–2269
(2000). http://dx.doi.org/10.1126/science.290.5500.2268 SCIEAS 0036-8075 Google Scholar
J. B. Tenenbaumet al.,
“A global geometric framework for nonlinear dimensionality reduction,”
Science, 290
(5500), 2319
–2323
(2000). http://dx.doi.org/10.1126/science.290.5500.2319 SCIEAS 0036-8075 Google Scholar
S. T. RoweisL. K. Saul,
“Nonlinear dimensionality reduction by locally linear embedding,”
Science, 290
(5500), 2323
–2326
(2000). http://dx.doi.org/10.1126/science.290.5500.2323 SCIEAS 0036-8075 Google Scholar
M. BelkinP. Niyogi,
“Laplacian eigenmaps and spectral techniques for embedding and clustering,”
in Proc. Adv. Neural Inform. Process. Syst.,
585
–592
(2002). Google Scholar
X. HeP. Niyogi,
“Locality preserving projections,”
in Proc. 16th Conf. Neural Information Processing Systems,
103
(2003). Google Scholar
X. Heet al.,
“Neighborhood preserving embedding,”
in Proc. 11th International Conf. Computer Vision,
1208
–1213
(2005). Google Scholar
E. KokiopoulouY. Saad,
“Orthogonal neighborhood preserving projections: A projection-based dimensionality reduction technique,”
IEEE Trans. Pattern Anal. Mach. Intell., 29
(12), 2143
–2156
(2007). http://dx.doi.org/10.1109/TPAMI.2007.1131 ITPIDJ 0162-8828 Google Scholar
H. Caiet al.,
“ISAR target recognition based on manifold learning,”
in Proc. IET International Radar Conf.,
1
–4
(2009). Google Scholar
B. Wanget al.,
“A feature extraction method for synthetic aperture radar (SAR) automatic target recognition based on maximum interclass distance,”
Sci. China Tech. Sci., 54
(9), 2520
–2524
(2011). http://dx.doi.org/10.1007/s11431-011-4430-0 SCTSBO 1674-7321 Google Scholar
H. T. Chenet al.,
“Local discriminant embedding and its variants,”
in IEEE Computer Society Conf. Computer Vision and Pattern Recognition,
846
–853
(2005). Google Scholar
M. Bryant,
“Target signature manifold methods applied to MSTAR dataset: preliminary results,”
Proc. SPIE, 4382 389
–394
(2001). http://dx.doi.org/10.1117/12.438232 PSISDG 0277-786X Google Scholar
V. Venkataramanet al.,
“Automated target tracking and recognition using coupled view and identity manifolds for shape representation,”
EURASIP J. Adv. Sig. Proc., 2011
(1), 1
–17
(2011). http://dx.doi.org/10.1186/1687-6180-2011-124 Google Scholar
R. A. Fisher,
“The use of multiple measurements in taxonomic problems,”
Ann. Human Gen., 7
(2), 179
–188
(1936). http://dx.doi.org/10.1111/j.1469-1809.1936.tb02137.x ANHGAA 0003-4800 Google Scholar
T. Rosset al.,
“Standard SAR ATR evaluation experiments using the MSTAR public release dataset,”
Proc. SPIE, 3370 566
–573
(1998). http://dx.doi.org/10.1117/12.321859 PSISDG 0277-786X Google Scholar
T. Wang,
“SAR automatic target recognition method research based on manifold learning,”
http://d.g.wanfangdata.com.cn/Thesis_Y1707370.aspx Google Scholar
L. M. Novaket al.,
“Performance of a high-resolution polarimetric SAR automatic target recognition system,”
Lincoln Lab. J., 6
(1), 11
–24
(1993). Google Scholar
T. Wanget al.,
“SAR ATR based on generalized principal component analysis integrating class information,”
in Proc. IET International Radar Conf.,
1
–4
(2009). Google Scholar
R. C. GonzalezR. E. Woods, Digital Image Processing, 80
–84 Prentice Hall, New Jersey
(2008). Google Scholar
, “The AT&T Database of Faces,”
(2002) http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html Google Scholar
S. TheodoridisK. Koutroumbas, Pattern Recognition, 280
–299 Elsevier Inc., Amsterdam, Holland
(2011). Google Scholar
T. Cover,
“Estimation by the nearest neighbor rule,”
IEEE Trans. Inform. Theory, 14
(1), 50
–55
(1968). http://dx.doi.org/10.1109/TIT.1968.1054098 IETTAW 0018-9448 Google Scholar
A. M. MartinezA. C. Kak,
“PCA versus LDA,”
IEEE Trans. Pattern Anal. Mach. Intell., 23
(2), 228
–233
(2001). http://dx.doi.org/10.1109/34.908974 ITPIDJ 0162-8828 Google Scholar
A. K. Mishraet al.,
“Automatic target recognition,”
Encyclopedia of Aerospace Engineering, John Wiley & Sons Ltd., Hoboken, New Jersey
(2010). Google Scholar
N. MekuzJ. Tsotsos,
“Parameterless ISOMAP with adaptive neighborhood selection,”
Pattern Recognition, 364
–373 Springer, Berlin, Heidelberg
(2006). Google Scholar
Y. Shuichenget al.,
“Graph embedding and extensions: A general framework for dimensionality reduction,”
IEEE Trans. Pattern Anal. Mach. Intell., 29
(1), 40
–51
(2007). http://dx.doi.org/10.1109/TPAMI.2007.250598 ITPIDJ 0162-8828 Google Scholar
Biography Jifang Pei received a BS from the College of Information Engineering at Xiangtan University, Hunan, China, in 2010. He is an IEEE student member and is working toward an MSc degree at the University of Electronic Science and Technology of China (UESTC), Chengdu. His research interests include SAR automatic target recognition and digital image processing.  Yulin Huang received his BS and PhD degrees in electronic engineering from the University of Electronic Science and Technology of China, Chengdu, in 2002 and 2008, respectively. He is an IEEE member and an associate professor at UESTC. His fields of interest include radar signal processing and SAR automatic target recognition.  Xian Liu received a BS degree from the Institute of Information Science and Engineering at Hebei University of Science and Technology, China, in 2009. She is an IEEE student member and is working toward a PhD degree at UESTC. Her fields of interest include SAR automatic target recognition.  Jianyu Yang received a BS degree from the National University of Defense Technology, Changsha, China, in 1984, and MS and PhD degrees from UESTC in 1987 and 1991, respectively. All his degrees are in electronic engineering. He is a professor at UESTC and a senior editor for the Chinese Journal of Radio Science. He is a member of IEEE and the Institution of Engineering and Technology and a senior member of the Chinese Institute of Electronics. |