|
|
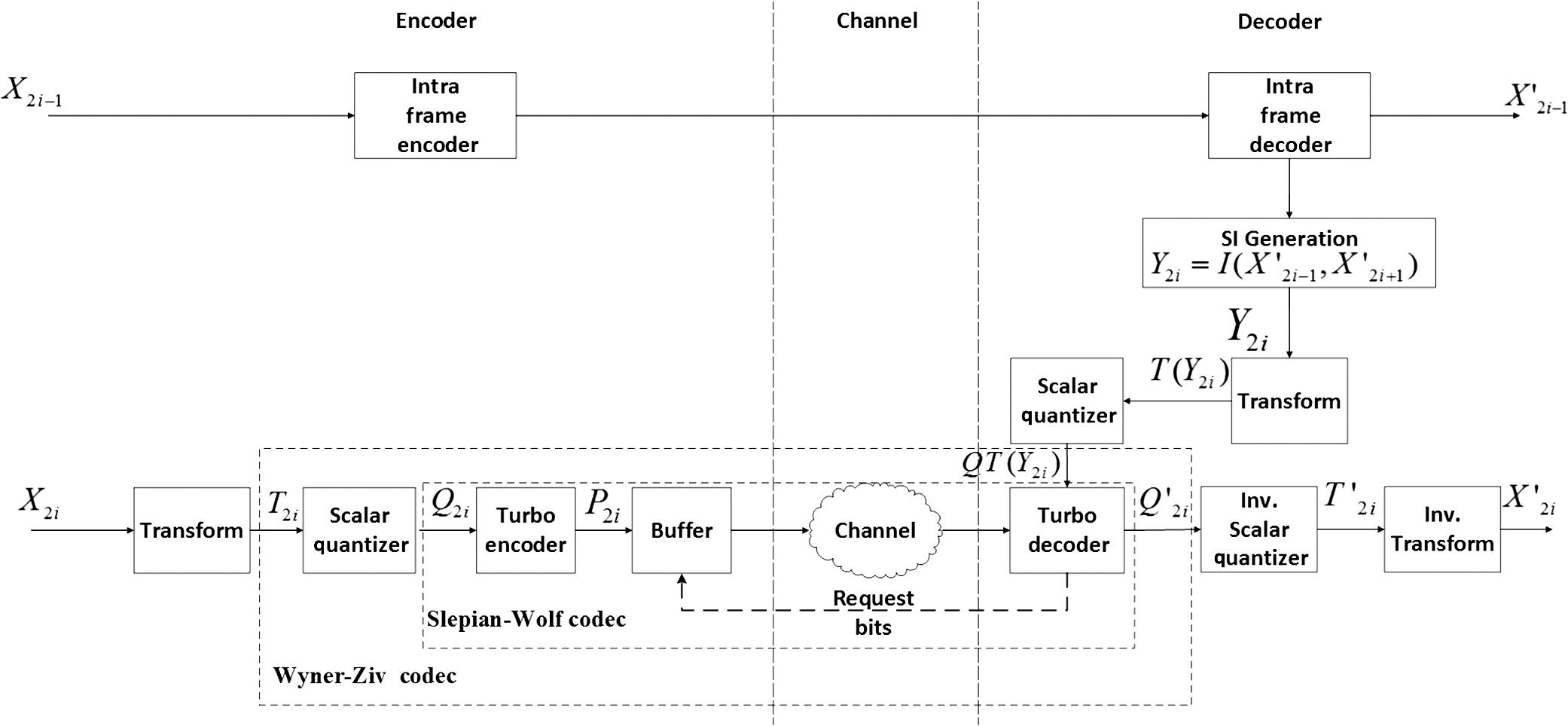
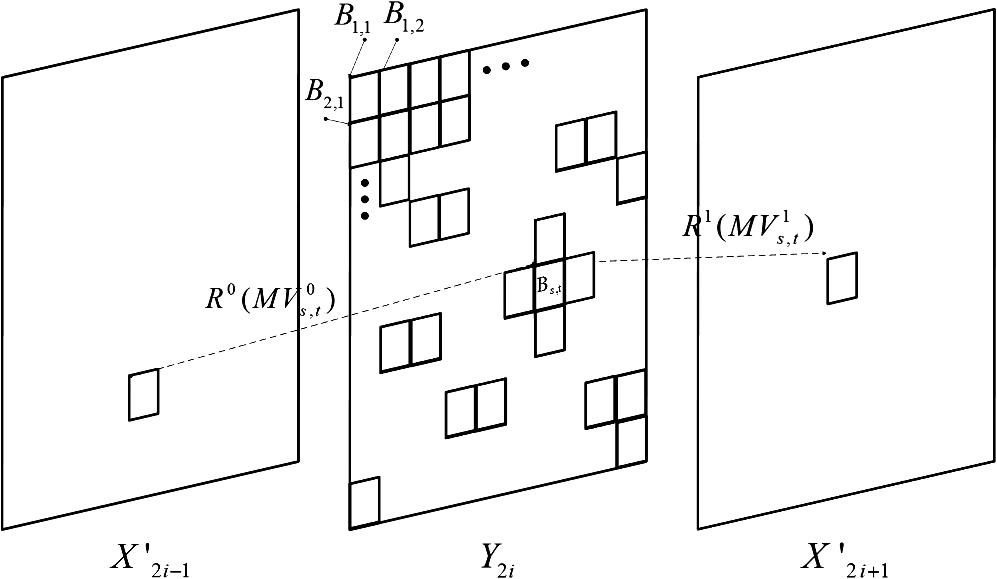
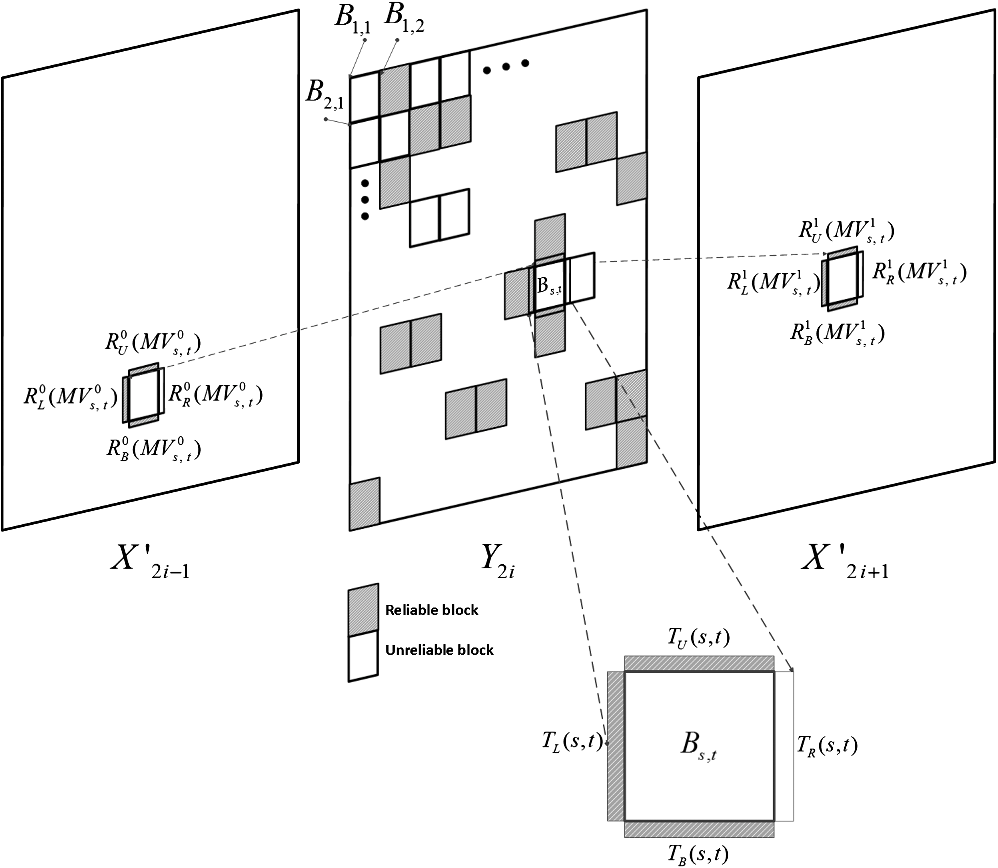
1.IntroductionIn the last few years, a variety of mobile multimedia devices have been developed and become popular. The end-users would like to capture various scenes and to send those through up-link channels. Usually, the capability of the mobile devices that the end-users have is constrained with low-power and low-CPU speed. In this circumstance, the conventional video codecs, such as MPEG-2, H.264/AVC, and MPEG-4, are not appropriate for the portable devices because those codecs need the high power to encode video sequences. Thus, demand for simple and low-power video encoder has been continuously increasing. Distributed video codec (DVC) is one of the solutions to encode video sequence with low complexity on the encoder side. The complexity of DVC encoder is significantly lower than those of the conventional encoders. DVC codec is regarded as an advanced codec that is appropriate for low power applications such as wireless surveillance, sensor network, and mobile camera phones. DVC had been developed based on Slepian–Wolf1 and the Wyner–Ziv2 theorems which had proved that two signals can be decoded with prediction on the decoder side after those signals have been encoded without prediction between them on the encoder side. A theoretical method for lossless coding with side information (SI) was performed in Ref. 1. This method is referred to as Slepian–Wolf coding and is used with a channel-coding scheme. Slepian–Wolf coding was extended to a lossy compression by Wyner and Ziv.2,3 The Wyner–Ziv codec consists of a quantization module, channel coding module, such as turbo code and low-density parity-check accumulator, punctured matrix, and SI generator. Most DVC codecs have been developed based on the models4,5 which Stanford University and University of California Berkeley have provided. The model of UC Berkeley is named power-efficient robust, high-compression, syndrome-based multimedia (PRISM) coding.5 In Ref. 6, a project, which is called distributed coding for video services (DISCOVER), had been performed to construct the low-power video codec based on Slepian–Wolf and Wyner–Ziv theorems. In DISCOVER codec, key frames were encoded with the conventional intra-coding technique (intra-mode of H.264/AVC). On the other hand, the Wyner–Ziv frames were split to nonoverlapped blocks and then the blocks were transformed and quantized. The quantized coefficients were ordered bit plane by bit plane. Those coefficients were fed into a systematic channel encoder. Recently, practical coding techniques using Slepian–Wolf and Wyner–Ziv codecs have been further studied.7–11 Qing et al.7 proposed a model for the correlation of noise statistics, which was utilized to increase coding performance. Coding performances of various DVC codecs were analyzed in Ref. 8, where motion vectors (MVs) were estimated with subpixel resolution to generate SI. In Refs. 910.–11, enhanced SI was generated using various algorithms. Petrazzuoli et al.9 proposed a method to generate the SI, where more than two intra-decoded frames are used to estimate the position of the current MC block. A bilateral ME-based scheme to generate SI was described in Ref. 10. In Ref. 11, SI was generated using a side matching algorithm. Among the tools to increase the performance of the DVC codec, an efficient scheme to generate the SI frame is one of the most important techniques because it dominantly affects the quality of the picture in the DVC decoder and the encoding rate. In this paper, we propose a scheme to generate the SI frame using block boundary matching after analyzing the coding blocks in the initial SI frame. The main functions of the SI generation module are motion estimation (ME) and motion compensation (MC). Thus, it is important to estimate MVs efficiently in DVC decoder. Because this topic is crucial also in a variety of video codecs,12–17 for several decades, the related researches have been performed by various researchers to increase the accuracy of MVs,12–14 and to speed up the ME process.15–17 In this paper, we propose an efficient scheme to estimate MVs while the specific properties of MVs in DVC decoder are considering. This paper is organized as follows. In Sec. 2, the model for DVC codec is formulated. The proposed scheme is explained in Sec. 3. Simulation results are presented in Sec. 4. Section 5 concludes this paper. 2.Wyner–Ziv Codec ModelFigure 1 shows a video communication system that incorporates the Wyner–Ziv (WZ) codec. In this system, the odd frames are encoded using the intra-coding mode of the H.264/AVC standard,18 while the even frames are encoded using the WZ codec which consists of a Slepian–Wolf coding module and an outer quantizer-reconstruction pair. The data generated from encoding intra-frame and WZ frame are transmitted separately over independent channels. We assume that the channel for intra-frame is robust enough to prevent channel errors. and are the decoded frames on the decoder side. When a WZ frame is encoded on the encoder side, the frame is split to nonoverlapped blocks and the blocks are transformed by discrete cosine transform (DCT). The transformed frame is denoted by . The DCT transformed frame is quantized by a scalar quantizer. The quantized frame is denoted by , where a quantized datum is represented by a binary index. The binary indexes are encoded using a turbo coder to protect it from channel error. The turbo encoder changes each binary index to another binary vector which consists of information and redundant bits. Among the resulted bits, only the redundant bits are transmitted to the decoder, whereas the information bits are not sent. The set of binary vectors which turbo encoder generates is denoted by . On the decoder side, while the odd frames are reconstructed by the H.264/AVC decoder with the intra-mode, the even frames are made by WZ decoder. In decoding WZ frames, when the quantized frame is generated by the turbo decoder both redundant and information bits are needed. But because the information bits have not been sent from the encoder, the turbo decoder should use the prediction values for the information bits. In Fig. 1, is used instead of the information bits, where is SI frame. is constructed using ME and MC for the previous and next intra-frames, and , that have been reconstructed by H.264/AVC decoder. is resulted from quantizing after DCT transforming . After the turbo decoder has generated , the decoded WZ frame is reconstructed by applying inverse DCT after inverse quantizing the . Because the is made using , the quality of depends on the quality of . Therefore, various research9–11 has been performed to increase the quality of the SI frame. Petrazzuoli et al.9 proposed a method to generate the SI where more than two intra-decoded frames are used to estimate the position of the current MC block. In the first step of Ref. 9, temporary MVs are estimated from to . Then, the half-sized vectors of the temporary MVs are used as MVs for the corresponding blocks in the SI frame. This step provides a temporary SI frame. In the next step, new forward and backward MVs are estimated from to and , respectively. Based on the forward and backward MVs, the SI frame is refined. In Ref. 10, a bilateral ME-based scheme to generate SI frame had been proposed, where side matching distortion was used in the ME process. In the initial step of Ref. 10, seed blocks were selected to increase the performance of ME process, which increases the quality of SI frame. Ko et al.11 had proposed an algorithm to generate SI frame using a side matching algorithm, where blocks in SI frame were refined considering the mismatch error between the template of the current blocks and the corresponding pixels in the intra-frames and . In this paper, we make an initial SI frame by using ME and MC processes where these procedures are not constrained by a specific algorithm. One of the conventional ME and MC schemes can be used in this step. Because the qualities of some blocks in the initial SI frame may be very low, the blocks are refined according to the reliabilities of the blocks. The reliability of each block is calculated using the concentration ratio of MVs of the neighbor blocks. 3.Proposed AlgorithmThe proposed scheme consists of three steps to generate the SI frame. The initial SI frame is constructed by using forward, backward, and bidirectional ME and MC between and in the first step. Then, the blocks in SI frame are analyzed in the second step. Finally, in the third step, the SI frame is refined using the information generated in the second step. 3.1.First Step: Generating the Initial SIIn the first step, a temporary SI frame is constructed by ME and MC for and . After temporary backward and forward MVs are estimated from to and to , respectively, the first temporary SI frame is constructed by MC based on the temporary MVs. Then, new forward and backward MVs are estimated from the first temporary SI frame to and , respectively. By using the MC based on the new forward and backward MVs, the second temporary SI frame is constructed. Figure 2 shows the relationship between the two key frames (, ) and the second temporary SI frame (). In , a block whose size is is constructed by ME and MC. and denote the horizontal and vertical indexes of the block in . and are the MVs estimated for and , respectively, to reconstruct . The superscript 0 and 1 imply the backward and forward data, respectively. The horizontal and vertical components of are denoted by and , respectively, where the superscript is 0 or 1. As can be seen from other researches,9–11 it is difficult for the temporary SI frame to demonstrate high quality because the ME and MC modules generate some poor quality blocks. 3.2.Second Step: Evaluating the ReliabilityIn the second step, the reliability of each is evaluated. If a has high quality, then the MVs of the are highly correlated to those of the neighboring blocks. To describe the neighbor blocks, we define two sets related to the neighboring blocks with and . is a set of the neighbor blocks of the current block . Adding the current block to results in the extended set . Note that the number of blocks in and are 8 and 9, respectively. If the variance of MVs of blocks in is smaller than that of blocks in , it means that adding MVs of to the set of MVs of blocks in increases the concentration of MVs. This case implies the quality of is high and the block is reliable. The variance of MVs can be evaluated by using eigenvalues of the covariance matrix of the MVs. The covariance matrixes of MVs related to and are whereIn the above equations, and are the sets of ’s of blocks in and , respectively. ,, , and are the mean values of and in and , respectively. If the eigenvalues of and are denoted by , , , and , respectively, the reliability of the block is defined as follows: If the block is made using the ME and MC from only the previous intra-coded frame or only the next frame , then the reliability of Eq. (9) becomes or respectively. In Eqs. (9)–(11), as the value of becomes smaller, the MVs in become more locally concentrated. Therefore, the state of refers to the case in which adding to results in an increased concentration of . This implies that if the of a block is larger than those of the other blocks, the quality of the block is higher than others.3.3.Third Step: Refinement of BlocksIn this step, if ’s of some blocks are , then the blocks are classified as unreliable and remade. On the other hand, if ’s of some blocks are not , then the blocks are classified as reliable. After the unreliable blocks are sorted in a decreasing order of their ‘s, those are remade in the order by ME/MC procedure using block boundary matching (BBM). Figure 3 shows that an SI frame consists of reliable and unreliable blocks. Because the neighbor reliable blocks can be used to remake the unreliable block , the MV of is re-estimated with templates , , , and which are the upper, bottom, left, and right templates, respectively. Note that those templates consist of pixels in neighbor reliable blocks. If some neighbor blocks around the current unreliable block are unreliable, then the corresponding templates are not used. The MV of is estimated by minimizing the following cost function: where superscripts “” and “” imply that the data are related to and , respectively. , , , and are sets of pixels in reference frames whose pixels are overlapped with templates , , , and displaced by , respectively. denotes the mean-squared difference between and , where is one of the . If is used because it is included in the reliable neighbor block, then is set to 1, otherwise, it is set to 0. If ME/MC is performed with forward or backward only, then the corresponding one in is used in Eq. (12). The variable is the number of pixels used to calculate the cost function of Eq. (12).4.Simulation ResultsIn this section, the gain of the proposed scheme is represented by Bjøntegaard delta (BD) rate reduction.19 The intra-frames are encoded with the intra-mode of JM18.0. The number of frames to be encoded is 300. The GOP structure is “IWIWI…,” where “I” and “W” denote the intra- and WZ frames, respectively. When the intra- and WZ frames are encoded, the QPs are set to {27, 31, 35, 39} which are used in the calculation of BD rate reduction.19 Note that the quantization module of H.264/AVC is used for both intra- and WZ frames. In the decoders of DVC codecs, the MVs were estimated with pixel resolution. In Figs. 4 and 5, and Tables 1 and 2, the DVC codec incorporating the proposed scheme (BBM) is compared with DVC codecs using the conventional algorithms,9–11 where the size of is set to or . Figures 4 and 5 show that the rate-distortion (RD) curves of the DVC codecs using the proposed scheme are higher than those incorporating the conventional methods. It implies that the proposed scheme outperforms the conventional schemes in the viewpoint of RD. In Tables 1 and 2, the proposed algorithm has gains of , , and , , on average BD rates against the conventional schemes. Note that the negative number of BD rate implies that the proposed scheme reduces the total number of the bits generated from encoding the video sequence while the image quality resulted from the proposed scheme is equal to those of the conventional schemes. The gains of the case of are larger than that of because the template of block contains the more useful information to construct the SI frame than that of block. Fig. 4Comparison between rate-distortion (RD) curves of the conventional and the proposed algorithms, where the BBM is performed with . (a) Foreman, (b) mobile, (c) hall, (d) silent. 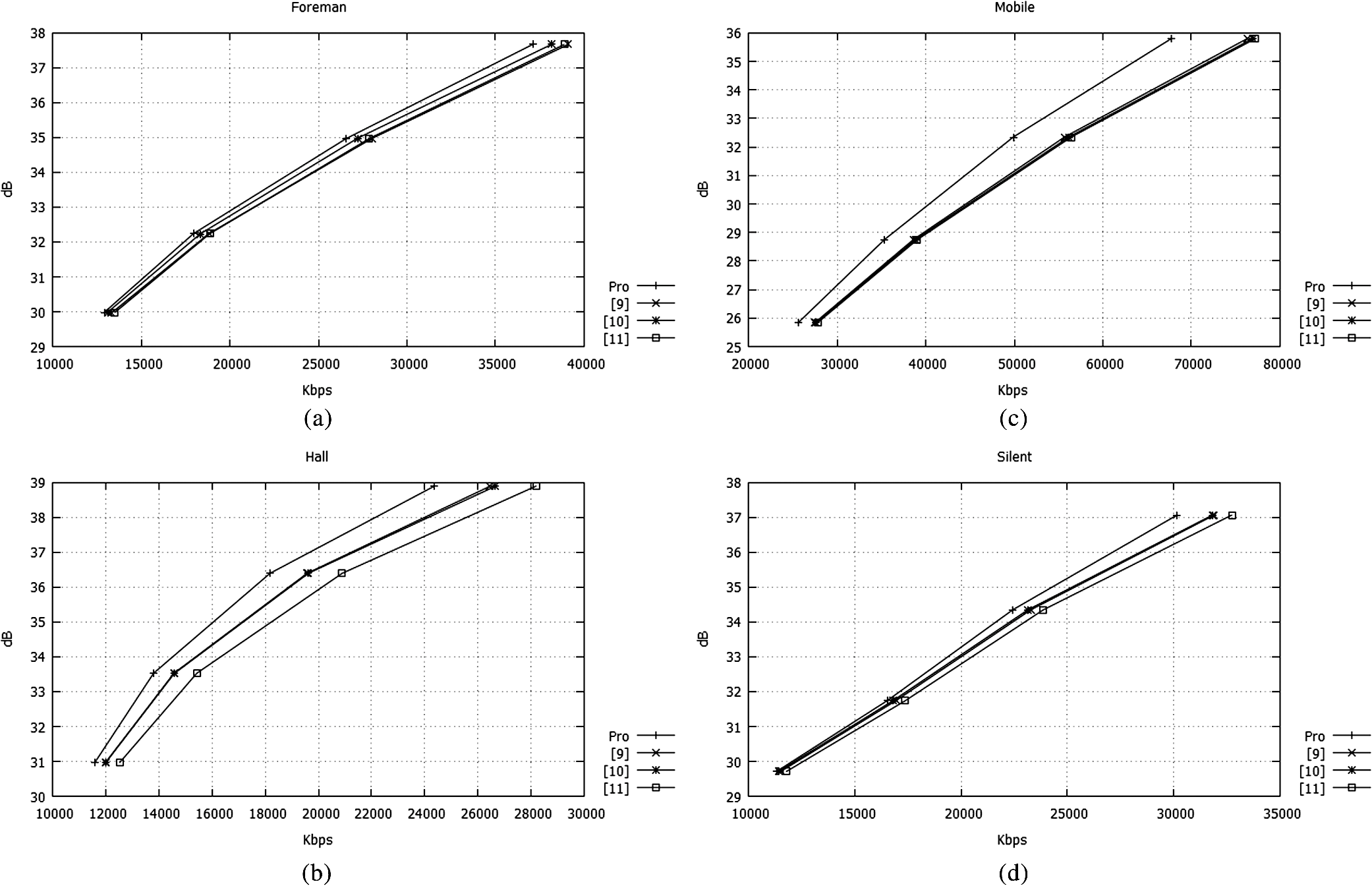 Fig. 5Comparison between RD curves of the conventional and the proposed algorithms, where the BBM is performed with . (a) Foreman, (b) mobile, (c) hall, (d) silent. 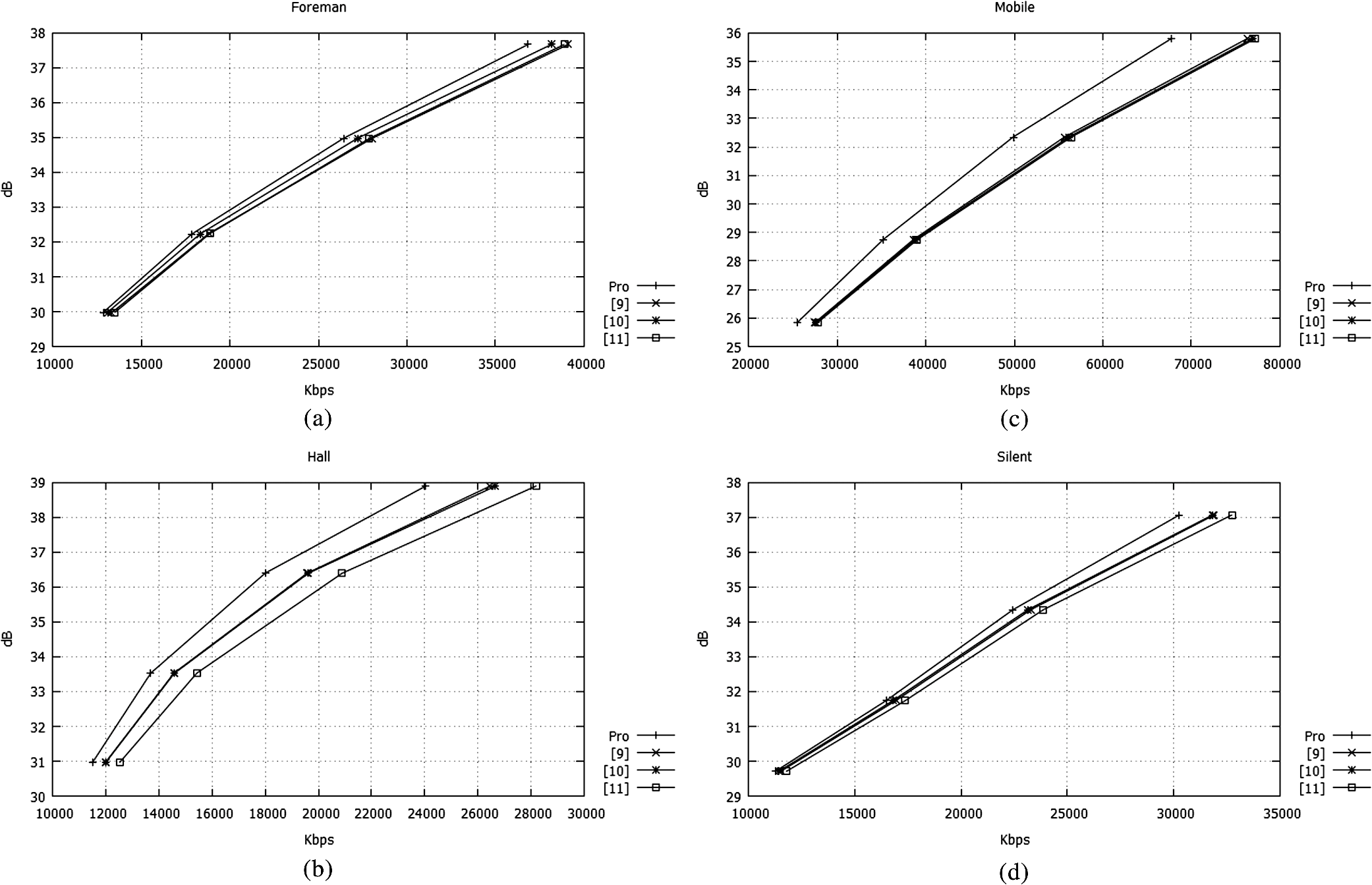 Table 1Bjøntegaard delta (BD) rate gains and the relative complexity of the proposed DVC codec. N×N=8×8.
Table 2BD rate gains and the relative complexity of the proposed DVC codec. N×N=16×16.
To understand the tendency of gains according to the block size, we show the relationship between the BD rate gain and the block size in Fig. 6, where the DVC codec incorporating BBM is compared with the DVC codec using the conventional algorithm.9 Although the performance depends on the test sequences, the overall gains show that the case of provides the best performance among three cases of the block size. The boundary template of is less useful to update the unreliable blocks than that of , because the number of pixels in the template of is smaller than that of . On the other hand, because in the case of , the correlation between pixels in a block and templates of the block is lower than that of the case of , the case of gives more gain than that of . Fig. 6Bjøntegaard delta rate gains of the DVC codec incorporating BBM according to the block sizes against the DVC codec using the conventional algorithm (Ref. 9). 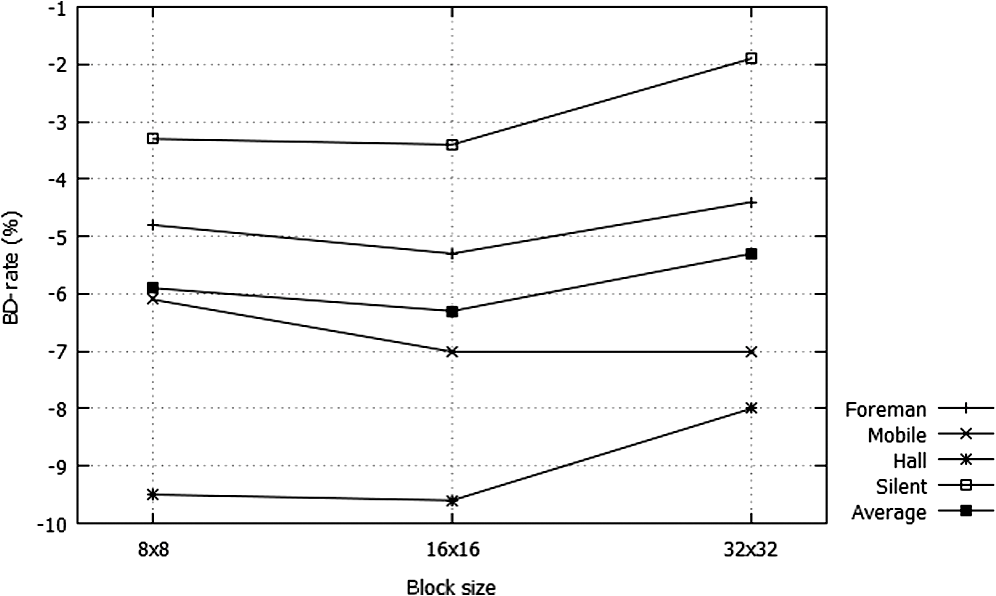 In Tables 1 and 2, the complexity of the DVC codec using the proposed scheme is between 97% and 105% of those using the conventional schemes. Note that 100% implies the complexity of the proposed scheme is equal to that of the conventional scheme. The complexities represented in the tables show that the complexity of the proposed scheme is approximately equal to those of the conventional schemes. Validity of the reconstructed SI has been checked in Table 3 where the averaged PSNRs of SI reconstructed in DVC decoder were measured. Even though it is not allowed in DVC scenario, it is helpful to check the accuracy of SI generation algorithms. As we can see from this table, the PSNRs of SI generated by the proposed BBM are higher than those resulting from the conventional algorithms. It implies that the proposed scheme outperforms the conventional algorithms in increasing the quality of the generated SI frame. Table 3Averaged PSNRs of the SI’s reconstructed in the DVC decoder. N×N=16×16.
To analyze the performances of the steps of the proposed algorithm, the percentage of the blocks regarded as unreliable in the proposed scheme is shown in Table 4, where the percentages of the unreliable blocks are . Although the portion is small, the gains resulted by updating the unreliable blocks are significant. In this table, we measure BD rate gains of the third step against the first step of the proposed scheme. This table shows that the third step of the proposed algorithm increase the coding efficiency significantly. Table 4Percentage of the unreliable blocks in the proposed scheme. BD rate gains of the third step against the first step in the proposed scheme. N×N=16×16.
The second and third steps of the proposed scheme described in Sec. 3 can be used to enhance the performance of the conventional algorithms,9–11 because the steps increase the quality of the SI frame by updating those that have been made by the conventional algorithms. To demonstrate it, the performance comparisons between DVC codecs using the combined techniques (conventional schemes + second and third steps of BBM) and the conventional schemes are represented in Table 5, where . In the DVC codec using the combined techniques, instead of the first step of the proposed algorithm, one of the conventional schemes is used to make the temporary SI frame. The temporary SI frame is updated by the second and third steps of the proposed algorithm. The DVC codecs using the combined techniques are more efficient than codecs using the conventional schemes. As for the results related to Ref. 9 in Table 5, the gains of the combined method are insignificant. Because SI frame constructed by Petrazzuoli et al.9 includes a lot of unreliable blocks, the number of reliable neighbor blocks that the BBM scheme can utilize is small. Note that BBM is useful when a lot of reliable neighbor blocks are included in the temporary SI frame. Table 5BD rate gains and the relative complexity of the DVC codec using the combined techniques. N×N=16×16.
In DVC codec, the complexity of the channel decoder (turbo decoder) decreases as the quality of the SI frame increases, because the number of operations sending more parity bits which are requested by the decoder is reduced as the quality of the SI frame increases. Therefore, in Table 5, because the quality of SI frame generated from the combined techniques is higher than those resulting from the conventional schemes, the complexity of the DVC codec using the combined techniques may be smaller than the conventional codecs. This table shows that the proposed scheme (BBM) can be used to increase the performances of the conventional schemes. 5.ConclusionsThis paper proposes an efficient method to reconstruct the SI frame in a DVC decoder. In the proposed algorithm, the blocks in the SI frame are classified to reliable and unreliable blocks, and then the unreliable blocks are remade using a BBM scheme. Simulation results show that the proposed scheme outperforms the conventional methods. The proposed scheme can be combined with the conventional schemes to increase the coding performance further. AcknowledgmentsThis work was supported in part by the Technology Innovation Program (Development of Super Resolution Image Scaler for 4K UHD) under Grant No. K10041900. This work was supported in part by the National Research Foundation of Korea (NRF) Grant funded by the Korean Government (MOE) (No. 2011-0011401). ReferencesD. SlepianJ. K. Wolf,
“Noiseless coding of correlated information sources,”
IEEE Trans. Inf. Theory, 19
(4), 471
–480
(1973). http://dx.doi.org/10.1109/TIT.1973.1055037 IETTAW 0018-9448 Google Scholar
A. D. WynerJ. Ziv,
“The rate-distortion function for source coding with side information at the decoder,”
IEEE Trans. Inf. Theory, 22
(1), 1
–10
(1976). http://dx.doi.org/10.1109/TIT.1976.1055508 IETTAW 0018-9448 Google Scholar
A. D. Wyner,
“On source coding with side information at the decoder,”
IEEE Trans. Inf. Theory, 21
(3), 2941
–300
(1975). http://dx.doi.org/10.1109/TIT.1975.1055374 IETTAW 0018-9448 Google Scholar
B. Girodet al.,
“Distributed video coding,”
Proc. IEEE, 93
(1), 71
–83
(2005). http://dx.doi.org/10.1109/JPROC.2004.839619 IEEPAD 0018-9219 Google Scholar
R. PuriK. Ramchandran,
“PRISM: a “reversed” multimedia coding paradigm,”
in Proc. IEEE Int. Conf. on Image Processing,
I-617
–I-620
(2003). Google Scholar
X. Artigaset al.,
“The DISCOVER codec: architecture, techniques and evaluation,”
in Picture Coding Symposium,
(2007). Google Scholar
L.-B. QingX.-H. HeR. Lv,
“Modeling non-stationary correlation noise statistics for Wyner–Ziv video coding,”
in International Conference on Wavelet Analysis and Pattern Recognition ‘07,
316
–320
(2007). Google Scholar
Z. LiL. LiuE. J. Delp,
“Rate-distortion analysis of motion side estimation in Wyner–Ziv video coding,”
IEEE Trans. Image Process., 16
(1), 98
–113
(2007). http://dx.doi.org/10.1109/TIP.2006.884934 IIPRE4 1057-7149 Google Scholar
G. PetrazzuoliM. CagnazzoB. P. Popescu,
“High order motion interpolation for side information improvement in DVC,”
in Proc. IEEE Int. Conf. on Acoustics Speech and Signal Processing 2010,
2342
–2345
(2010). Google Scholar
D. Y. KimD. S. JunH.W. Park,
“An efficient side information generation using seed blocks for distributed video coding,”
in Picture Coding Symposium,
86
–89
(2010). Google Scholar
B. KoH. ShimB. Jeon,
“Wyner–Ziv video coding with side matching for improved side information,”
in Pacific-Rim Symposium on Image and Video Technology 2007,
816
–825
(2007). Google Scholar
S.-C. Taiet al.,
“A multi-pass true motion estimation scheme with motion vector propagation for frame rate up-conversion applications,”
J. Display Technol., 4
(2), 188
–197
(2008). http://dx.doi.org/10.1109/JDT.2007.916014 IJDTAL 1551-319X Google Scholar
S. NikitidisS. ZafeiriouI. Pitas,
“Camera motion estimation using a novel online vector field model in particle filters,”
IEEE Trans. Circuits Syst. Video Technol., 18
(8), 1028
–1039
(2008). http://dx.doi.org/10.1109/TCSVT.2008.927107 ITCTEM 1051-8215 Google Scholar
K. R. Namuduri,
“Motion estimation using spatio-temporal contextual information,”
IEEE Trans. Circuits Syst. Video Technol., 14
(8), 1111
–1115
(2004). http://dx.doi.org/10.1109/TCSVT.2004.831975 ITCTEM 1051-8215 Google Scholar
P. C. ShenolikarS. P. Narote,
“Different approaches for motion estimation,”
in Int. Conf. on Control, Automation, Communication and Energy Conservation,
1
–4
(2009). Google Scholar
D. ZhangG. CaoX. Gu,
“Improved motion estimation based on motion region identification,”
in Int. Conf. on Systems and Informatics (ICSAI),
2034
–2037
(2012). Google Scholar
D. VuY. YangL. Bhuyan,
“An efficient dynamic multiple-candidate motion vector approach for GPU-based hierarchical motion estimation,”
in Int. Performance Computing and Communications Conference (IPCCC),
342
–351
(2012). Google Scholar
T. WiegandG. J. SulivanA. Luthra,
“, “Draft ITU-T Recommen- dation H.264 and Final Draft International Standard 14496-10 AVC,”
JVT of ISO/IEC JTC1/SC29/WG11 and ITU-TSG16/Q.6, Doc. JVT-G050r1,
(2003). Google Scholar
G. Bjøntegaard,
“Calculation of average PSNR differences between RD-curves,”
in ITU-T SG16 Q.6, VCEG-M33,
1
–5
(2001). Google Scholar
Biography Kwang-Hyun Choi received the BS degree from the Department of Information and Communication Engineering, Sejong University, Seoul, Republic of Korea, in 2012 and currently pursuing the MS degree from Sejong University. His research interests include video coding, signal processing, high efficiency video coding and three-dimensional high efficiency video coding.  Jae-Yung Lee received the BS and MS degrees from the Department of Information and Communication Engineering, Sejong University, Seoul, Republic of Korea, in 2011 and 2013, respectively, and is currently pursuing the PhD degree from Sejong University. His research interests include video coding, signal processing, high level syntax incorporated in high efficiency video coding (HEVC), scalable extension of HEVC (SHVC), and 3-D-HEVC.  Byeung-Woo Jeon received the BS degree (magna cum laude) in 1985, the MS degree in 1987 in electronics engineering from Seoul National University, Seoul, Republic of Korea, and the PhD degree in electrical engineering from Purdue University, West Lafayette, Indiana, in 1992. From 1993 to 1997, he was in the Signal Processing Laboratory, Samsung Electronics, Republic of Korea, where he conducted research and development into video compression algorithms, the design of digital broadcasting satellite receivers, and other MPEG-related research for multimedia applications. Since September 1997, he has been with the Faculty of the School of Information and Communication Engineering, Sungkyunkwan University, Korea, where he is currently a professor.  Jong-Ki Han received the BS, MS, and PhD degrees in electrical engineering from Korea Advanced Institute of Science and Technology (KAIST), Taejon, Korea, in 1992, 1994, and 1999, respectively. From 1999 to 2001, he was a member of technical staff with the Corporate R&D Center, Samsung Electronics Company, Suwon, South Korea. He is currently a professor with the Department of Information and Communications Engineering, Sejong University, Seoul, Republic of Korea. His research interests include image and video coding, transcoding, and signal processing for video sequence. He has participated in standardization of high efficiency video coding (HEVC) since 2010. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||