|
|
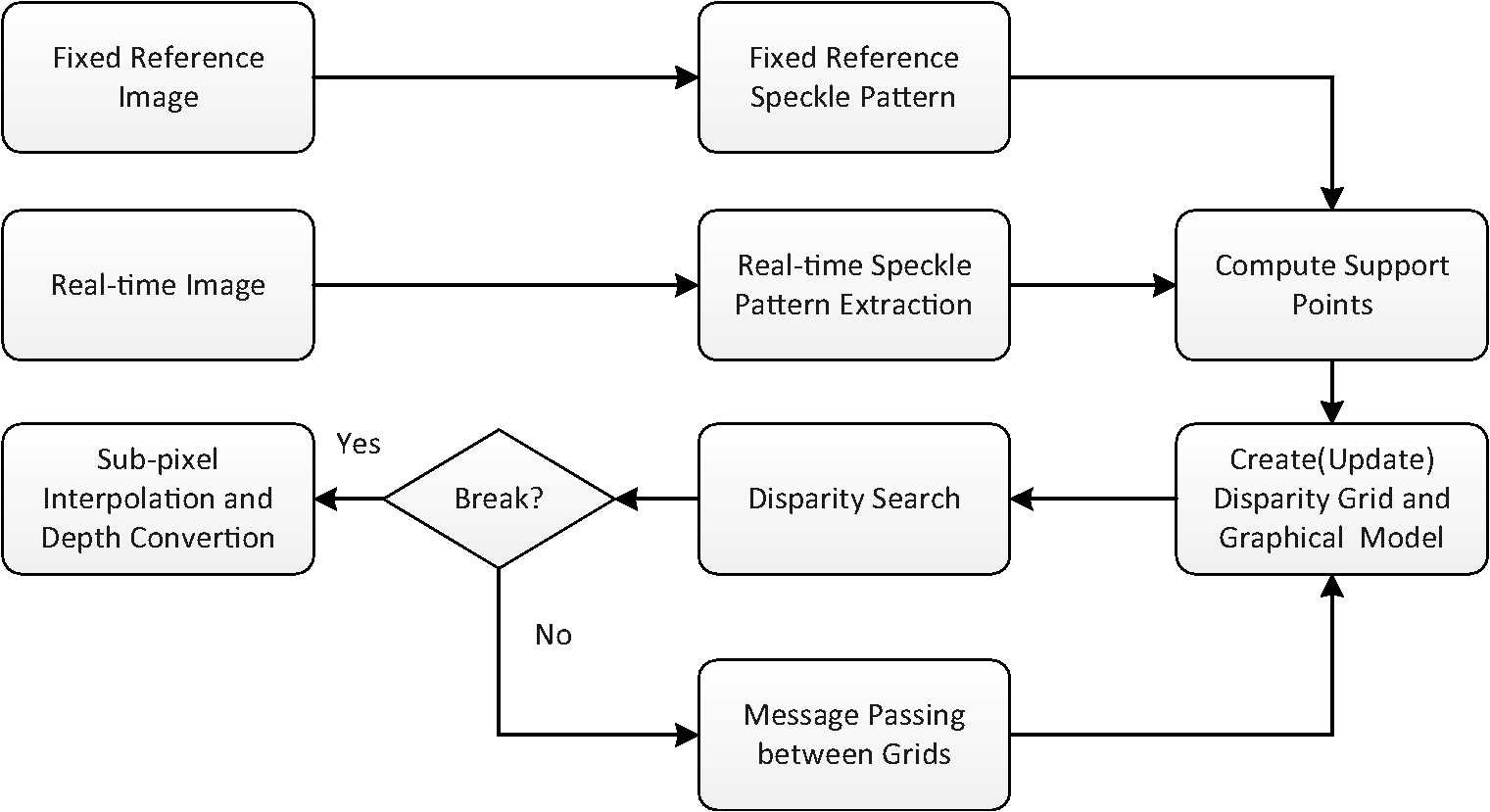
1.IntroductionDepth estimation is a basic problem in computer vision, widely applied in fields as diverse as automatic driving, shape measurement in industry, biomedical imaging, and human-computer interaction. Refer to Ref. 1 for an overview. In recent years, estimating depth by speckle projection has attracted considerable attention. Siebert and Marshall2 introduced three structures of speckle systems to capture three-dimensional (3-D) human body. Garcia et al.3 used ground glass to generate speckles and computed depth by correlating the captured image with reference images at different depth layers. Chen and Chen4 projected speckles with a common projector and built up a binocular system. Schaffer et al.5 used a laser and a diffuser to generate speckles and computed the depth using a temporal correlation method. However, these systems are restricted to near range and cannot be applied in bright environment due to the use of visual light. Recently, researchers tended to use infrared projectors and cameras6,7 to expand the sensing range for indoor applications. In these systems, the depth was estimated by stereo matching8 between the real-time captured image and the reference image. However, the high contrast of speckles could not be well handled by conventional methods. Wang et al.9 utilized adaptive binarization to handle the high contrast and proposed a progressive approach to estimate the depth map. Nevertheless, none of the approaches mentioned has considered the impact of ambient lighting. To tackle these problems, in this paper, we propose a novel approach to sense the indoor depth information. In our system, infrared laser speckle pattern is projected onto the scene and a single camera is used to capture images. First, we propose a novel direct-global separation approach to remove the ambient lighting and extract the pure speckle pattern. After that, a set of sparse support points are selected. Then a disparity grid is built upon these support points and a generative graphical model is introduced to search disparities. We propagate messages between blocks and update the disparities and the model iteratively. Finally, the depth map can be obtained by transforming the disparities into depth values. The experiments demonstrate the efficiency and effectiveness of our approach. The rest of this paper is organized as follows. In Sec. 2, we present the system structure and the framework of the algorithm. The preprocessing, including speckle pattern extraction and feature computing, is introduced in Sec. 3. Section 4 presents how to build the graphical model and search for the disparities with this model. Experimental results are presented in Sec. 5. In the last section, we make a conclusion and a discussion of future work. 2.System Structure and Algorithm FrameworkAs shown in Fig. 1, the system is made up of one pattern projector and one infrared digital camera. We use the Kinect’s projector, which consists of an infrared laser generator and a diffuser, to project the speckle pattern onto the scene. Aligned with the projector in and direction, the infrared camera captures the real-time speckle pattern reflected by the scene. Figure 2 gives an example of the inputs of our scheme, a real-time image and a fixed reference image. The reference image is a flat plane perpendicular to the optical axis, captured at a certain distance. Thus, the setup is equivalent to a binocular system. The depth can be computed by estimating disparities between the real-time image and the reference image. Figure 3 presents the framework of our proposed approach. First, we separate the direct component from the image to extract the pure speckle pattern. With this speckle pattern, we compute the matching costs of both left-to-right and right-to-left. Sparse support points are selected by evaluating the matching cost and left-right consistency. Then a disparity grid is built upon these support points. For each block in the disparity grid, we introduce a generative graphical model to represent the relationship between the support points and the unmatched points. Thus, disparities are computed by minimizing an energy function derived from the graphical model. The new reliably matched points are added as support points, and the graphical model is updated. Such process is repeated until convergence. Finally, the depth map is obtained by subpixel interpolation and transformation. 3.Speckle Pattern Extraction and Feature ComputingAs the illumination of real-time captured image and the reference image can be significantly different, it is not reliable to simply utilize local intensities10 to describe the speckles. To better describe the speckles, we first extract the pure speckle pattern, which is represented by binary features. Note that the fixed reference image is processed only once. In the image, the intensity at , can be viewed as a combination of two components, namely direct and global,11 where is the direct component due to direct illumination for the speckle pattern, and is the global component due to ambient lighting. Nayar et al.11 used high-frequency illumination to separate the direct and global components with multiple images.In this work, we try to extract the direct component with a single image and obtain the pure speckle pattern. By analyzing tens of images captured under various illuminations, we find that the intensities of speckles are spatially nonuniform, while the smallest values in the neighborhood of a certain radius around the speckles are stationary. According to Ref. 12, the radius can be fixed as constant. Figure 4 presents a representative image patch. The red inset contains a single speckle of relatively low intensity and the green inset contains four visibly brighter speckles. It can be observed that the smallest value in the red inset is almost the same as that in the green inset. That is, in a window larger than , the lowest intensities reflect the global component. Fig. 4A sample of real-time image and local details at different locations. (a) Sample patch in real-time image. (b) Detail for red inset in (a). (c) Detail for green inset in (a).  Let , be the observed intensity values in a window of size , and , be its order statistics. The global component is estimated with the weighted average of these observations, with the weight defined asThe parameter is a constant that controls the weight of each point, i.e., the contribution of a point to the estimated global component. Thus, the direct component at can be estimated by The direct component, as the pure speckle pattern, is then utilized to compute the feature vector for each point. To describe a certain point, we apply the CENSUS transform13 in a window around it to form a binary feature vector, denoted as . Let , , be the estimated direct component with Eq. (4) in this window. The feature vector can be treated as a binary string formed by a sequence of one-bit digits, where is the center of the window, and is a step function,4.Depth Estimation with Iteratively Updated Graphical ModelOnce the features have been computed, we can compute correspondences between the real-time image and the reference image to estimate the disparities. Geiger et al.14 built a prior on the disparities by forming a triangulation on support points, which has been proved to be very effective. However, as there are out-of-range regions and non-Lambertian surfaces in the infrared images, the support points will not distribute as uniformly as that in their visual-light images. To cope with this problem, we built a disparity grid and introduced an iterative updating scheme inspired by Shi et al.15 and Wang et al.9 4.1.Support PointsSupport points are the points that can be robustly matched between the input image pair.16,17 In this work, we select support points by evaluating the matching cost and uniqueness. Let be an observation in the real-time image, defined as the concatenation of its image coordinates, , and a feature vector, . Let be the set of observations in the reference image that lie on the epipolar line associated with , with each observation formed as , in which is the disparity between and . The matching cost between and is measured by the distance of the feature vectors, where is a distance function. In this paper, Hamming distance is used. To get rid of ambiguous matches, only the points whose absolute difference between the best and second best matches is large enough are retained. The uniqueness is measured by the left-right consistency, i.e., correspondences are retained only if they can be matched from left-to-right and from right-to-left.9,144.2.Disparity Grid and Generative Graphical ModelTo merge the local information of the support points, we build a disparity grid on the real-time image by dividing the image into blocks, with each block of size . The grid structure is illustrated in Fig. 5(a). For each block, the disparities of support points inside it and those in its four-neighborhood blocks are taken as the candidate disparities for it. These disparities form a candidate disparity set , . This cross-block supporting scheme allows for the effective propagation of neighboring information between blocks. Fig. 5Disparity grid and graphical model. (a) Grid setup and cross-block supporting. (b) Graphical model. Observations and candidate disparities are conditionally independent given , the disparity between and . And observations in are conditionally independent given and . 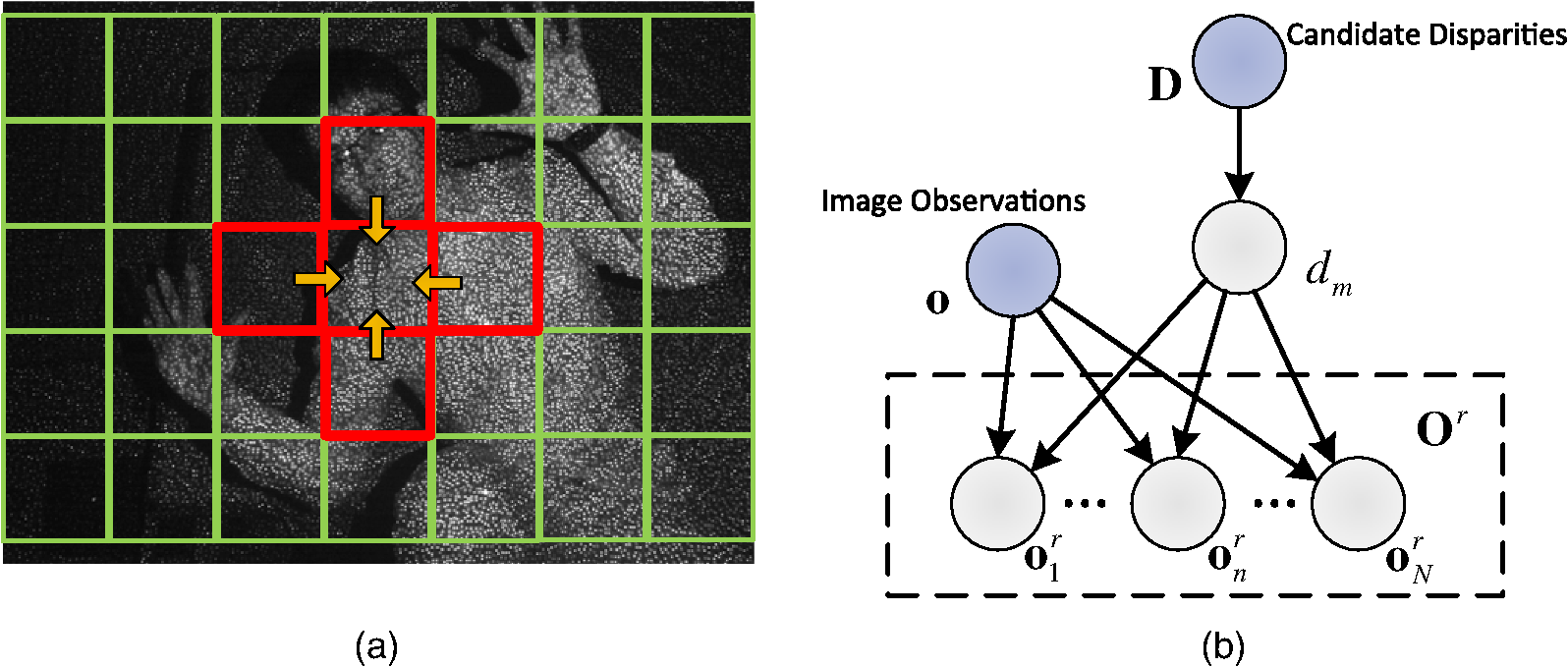 We propose a generative graphical model to model the relationship between the candidate disparities and the observations, and the relationship between observations, as shown in Fig. 5(b). Denote by the point we want to compute. These two relationships are described by two conditional independence assumptions:
By the first assumption, the joint probability is factorized as with being the likelihood, being the prior, and being the normalization factor. The prior can be modeled as an equally weighted Gaussian mixture modelA constrained Laplace distribution is applied to represent the likelihood: where is a positive number, with a typical value . The condition is derived from the fact that given a disparity, there is a deterministic mapping of in the reference image.Once the prior and likelihood are formulated, the disparity can be estimated by the maximum a posteriori estimation, where is the set of observations in the reference image that lie on the epipolar line associated with . Similar to Eq. (8), the posterior is factorized asBy the second independence assumption, the conditional distribution over can be further factorized as i.e., the product of all likelihoods. Note that the factorization in Eq. (13) holds and makes sense only if none of the likelihood takes on the zero value, which is the reason that is set to nonzero in Eq. (10). By plugging Eqs. (9), (10) and (13) into Eq. (12) and taking the negative logarithm, an energy function can be derived as follows: with being the feature vector at in the reference image, and being a constant associated with only. Now, the disparity for each point can be estimated by minimizing the energy function4.3.Iterative Model UpdatingFor out-of-range regions and non-Lambertian surfaces, the support points may not be sufficient. The disparity grid may not provide enough disparity information in these regions. To efficiently propagate the information between blocks, we propose an iterative scheme to update the support point set and the graphical model. The key of this iterative updating scheme is to select new reliably matched points during iterations. The energy in Eq. (14) itself is powerful to measure the reliability. Suppose for , the estimated disparity is . According to Eq. (14), the minimum matching energy is . The lower is, the more reliably is matched. We also use the confidence10,18 to describe the goodness of matching, which is defined as This definition indicates the difference between the minimum energy and the second-minimum one. Using both the matching energy and the confidence, we propose the iterative scheme presented in Algorithm 1 to update the model and search for , the optimal disparity for . At the beginning of each iteration, the matching energy and confidence for the points is computed with the current model. If the matching energy is lower than the current lowest matching energy , and the confidence is above some threshold , will be updated to . Furthermore, if the matching energy is lower than some threshold , this point is treated as reliably matched and will be added into . At the end of each iteration, the model is recomputed with the updated support point set . Algorithm 1Iterative model updating and optimal disparity searching.
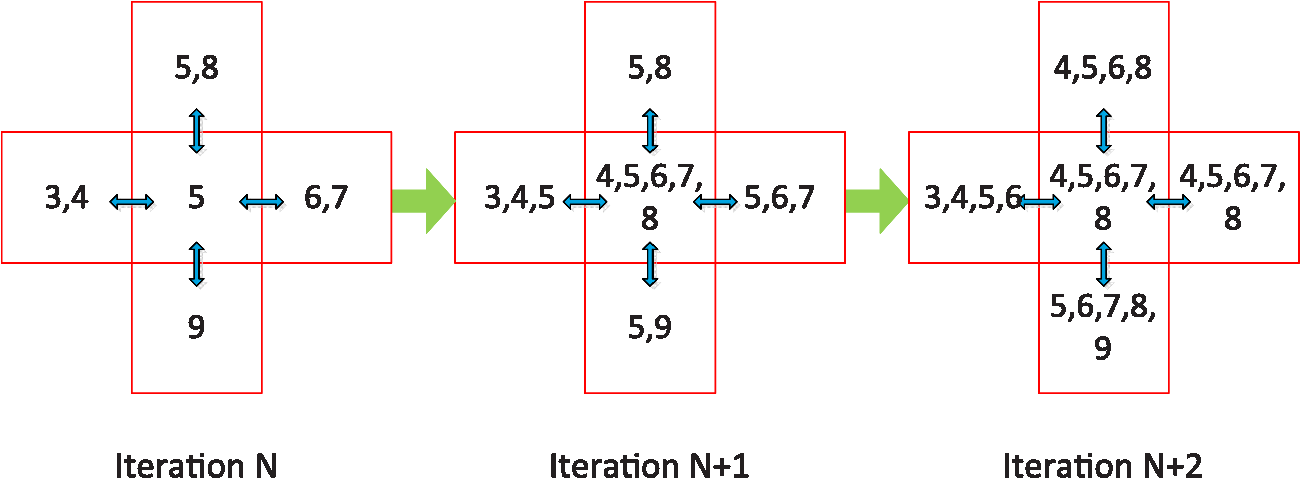
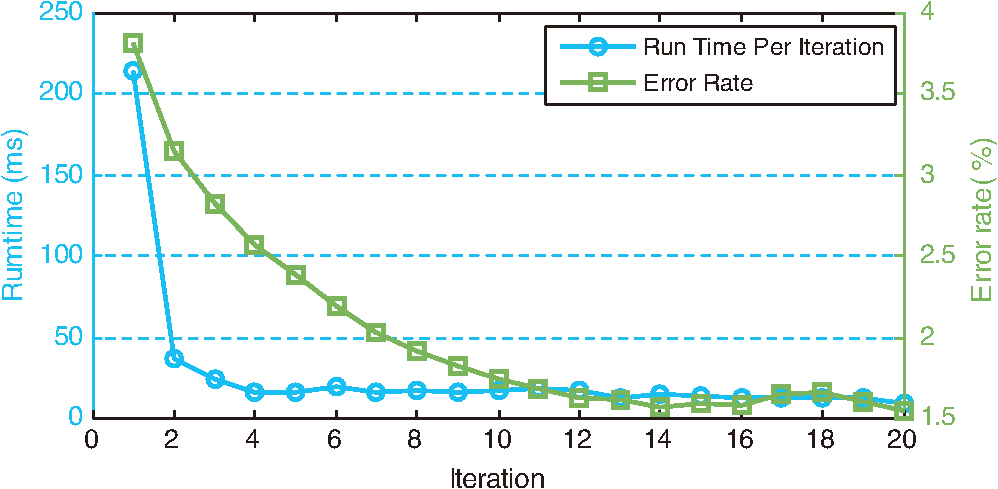
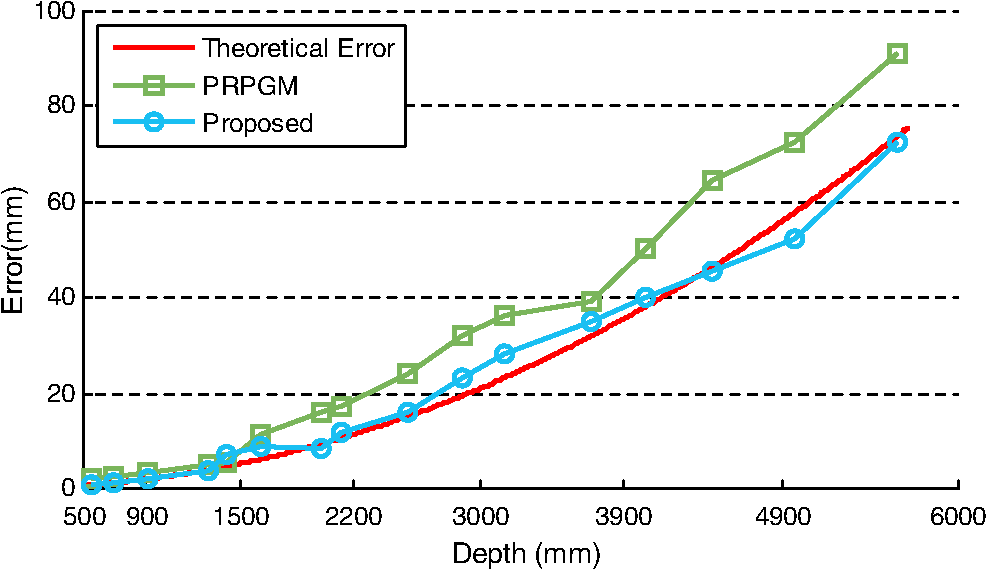
We note that because the blocks can support neighboring blocks, the newly added support points can be used to update not only the block they belong to but also the neighboring blocks. Thus, the messages can propagate between blocks during iterations. Meanwhile, the thresholds, and , can prevent the spurious messages from spreading out. Figure 6 gives an example of disparity messages propagating between blocks. 4.4.Subpixel Interpolation and Depth TransformationInterpolation has been adopted to achieve subpixel accuracy.19 We choose the linear interpolation method for its efficiency and effectiveness. Suppose the integer disparity for a point is , and the corresponding matching energy is . Let and , the subpixel disparity is computed by According to the triangular geometry, we can derive depth from disparity as where is a constant determined by the focal length of the camera and the equivalent baseline length, and is the depth of the reference plane.5.Experimental EvaluationTo evaluate the performance, we implement our approach in C++ on a desktop computer with 2.50 GHz Q9300 CPU and 4GB RAM. First, the effectiveness of pattern extraction and binary feature is presented. Then we show the efficiency and accuracy of the algorithm. Last, we give more results of several different scenes and compare our approach with other methods. Throughout all experiments, the parameters are fixed as , , , , , , . 5.1.Speckle Pattern Extraction and Binary FeatureAs shown in Fig. 7, except for defocus blurred and saturated regions, most of the direct components can be extracted clearly. To show the effectiveness of our speckle pattern extraction method and binary feature, we test the algorithm on a typical scene that contains surfaces of different depths. We run the algorithm with or without the speckle pattern extraction using the binary or intensity feature, four combinations in total. The comparison is presented in Fig. 8. Fig. 7Speckle pattern extraction result. (a) Original real-time image. (b) Global component (ambient lighting). (c) Direct component (speckle pattern). The green inset indicates a defocus blurred region, the red inset indicates a saturated region, and the blue inset indicates a normal region.  Fig. 8Effectiveness of speckle pattern extraction and binary feature. (a) Real-time image. (b) Using intensity feature without pattern extraction. (c) Using intensity feature with pattern extraction. (d) Using binary feature without pattern extraction. (e) Using binary feature with pattern extraction.  From Fig. 8, it can be observed that the result is the worst for the scheme without pattern extraction and with intensity feature, while the result is the best for our scheme with the pattern extraction and with binary feature. Especially, the result is greatly improved by our scheme in faraway regions. In these regions, the low contrast between the speckle pattern and the ambient lighting make the matches ambiguous. As the speckle pattern extraction can get rid of the ambient lighting’s influence and the binary feature is insensitive to contrast, the combination of them can significantly reduce the ambiguities. It can also be seen from the results that depth stripes are more obvious when using the intensity feature, though subpixel interpolation has been applied to all setups. This indicates that the binary feature can achieve a higher accuracy than the intensity feature. 5.2.Efficiency AnalysisTo show the efficiency of the proposed approach, we test the algorithm on a scene with one person inside. Figure 9 shows some results during iterations and the error map of the final result. It can be seen that our iterative message-passing scheme make the information propagate efficiently between blocks. The experimental results show that more reliably matched points are added earlier, which is in agreement with our analysis earlier. From the error map, we can see that the proposed approach is rather accurate except for some complex boundaries, e.g., the hands of the human. Figure 10 presents the convergence of the error rate and running time. The error rate is the percentage of bad pixels whose disparity error is over some tolerance (1 pixel in this paper). We convert depth into disparity with the inverse transform of Eq. (18) to compute error rates. It can be seen from Fig. 10 that after about 12 iterations, the error rate has converged to no more than 1.7%. The running time per iteration decreases so sharply that it almost converged to a constant after four iterations. Hence, we choose to terminate the process after 12 iterations, for the balance between accuracy and efficiency. On average, the proposed approach can process more than with the image resolution of . 5.3.Plane Test and Accuracy AnalysisWe test the algorithm on a series of planes to analyze the estimation accuracy. These images are captured with planes perpendicular to the optical axis of the camera at different distances. By assuming that the mean value of the depth map is an unbiased estimator for the plane, the standard deviation is used to measure the estimation error. According to the analysis in Ref. 20, the theoretical random error of depth measurement is proportional to the square distance from the sensor to the object. We compare the error of proposed method with the progressive reliable points growing matching (PRPGM) method introduced by Wang et al.,9 and the results are plotted in Fig. 11. The theoretical error is computed by assuming that the disparity estimation error is 0.2 pixel. The error curve shows that the error of the proposed algorithm coincides with the theoretical error. For long-range planes, the proposed method performs better than the PRPGM method and can achieve a gain about 3 dB in the absolute error. Besides, the largest relative error of our method is still , which verifies that the proposed approach can achieve an acceptable accuracy for different depth layers. 5.4.Scene TestTo demonstrate the wide applicability of our approach, we test our method on two videos. The first video is acquired with a fixed background and a human inside; the second is acquired with complex scenes, including different kinds of objects and non-Lambertian surfaces, such as LCD. We compare our approach with the normalized cross correlation (NCC)-based local window matching and the PRPGM method, both introduced in Ref. 9. To make the comparison fair, we apply the same speckle pattern extraction and subpixel interpolation to all three methods. Some representative frames are presented in Fig. 12, from which we can observe the following. Fig. 12Depth estimation under different scenes. The proposed method is compared with the NCC window matching and PRPGM method. 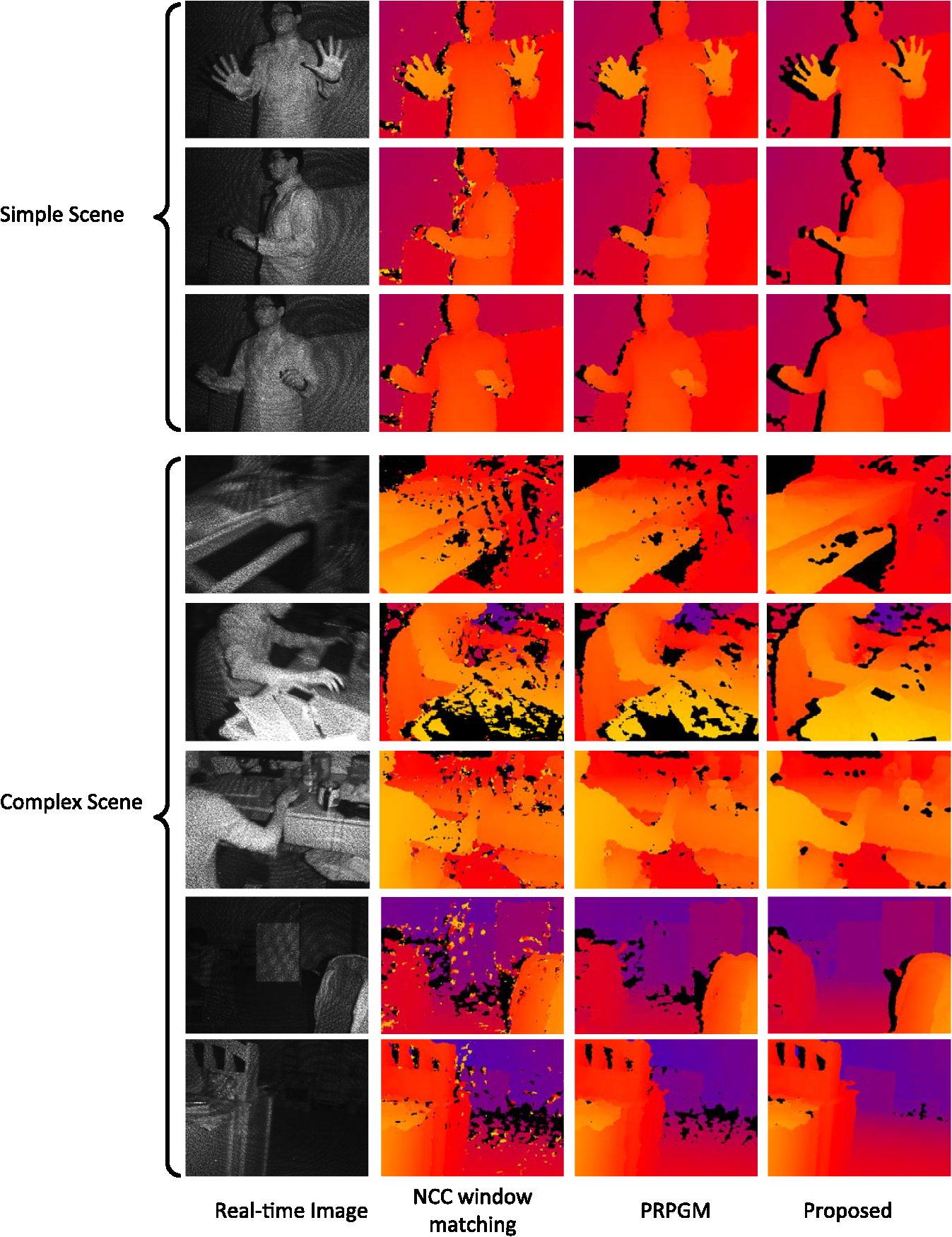 First, even though the speckle pattern extraction and the standard postprocessing are applied, there are still many mismatches left in the outcome of the NCC window matching. This indicates that the NCC method is not suitable to handle the speckle pattern, which is of high contrast. Second, the PRPGM method behaves better than the NCC method; it has fewer holes left. This is because the reliably matched points can act as seeds to pass their disparity information to their neighbors. However, as the seeds only send out messages to their immediate neighbors, the information spreads very slowly. Points in regions of fewer seeds, such as boundaries, may receive messages from incorrect seeds. Even worse, if they are too far away from the seeds, they can hardly receive useful messages. The low speed of message passing may lead to inaccurate boundaries and unmatched patches, in particular, for complex scenes. Third, the proposed method can cope with these problems. Through the cross-block support and the iterative model update, messages can pass on a scale of the block size. Therefore, regions with fewer support points can receive information from their neighboring blocks. Even the points in blocks of few support points can still gain substantial information after some iterations. Hence, more accurate boundaries can be obtained, and there are no unmatched patches left except for the regions where the speckle pattern cannot be extracted. The right-hand column of Fig. 12 demonstrates that our approach is widely applicable for different kinds of scenes. Figure 13 presents the error rate of the three methods over the two videos. The proposed method can achieve the best performance for most of the cases. In the simple scenes, the proposed method can reduce about 2% of the error points compared with the PRPGM method; in complex scenes, an even greater gain can be achieved. 6.Conclusion and Future WorkIn this paper, we have presented an active system to achieve effective depth sensing. We have shown that the speckle pattern extraction can effectively remove the ambient lighting, and the binary feature used is robust to contrast variation. The experiments have demonstrated that our iterative message-passing and model updating scheme can refine the disparity map efficiently, and our system is widely applicable. More importantly, the conditional independence in our graphical model makes it possible to process the points in parallel; thus the algorithm can be accelerated with graphics processing unit and field programmable gata array. To increase the robustness of our method, we intend to search for more robust preprocessing method, and a further plan is to refine the depth map by using the texture information of the scene. ReferencesF. ChenG. M. BrownM. Song,
“Overview of three-dimensional shape measurement using optical methods,”
Opt. Eng., 39
(1), 10
–22
(2000). http://dx.doi.org/10.1117/1.602438 OPEGAR 0091-3286 Google Scholar
J. P. SiebertS. J. Marshall,
“Human body 3D imaging by speckle texture projection photogrammetry,”
Sensor Rev., 20
(3), 218
–226
(2000). http://dx.doi.org/10.1108/02602280010372368 SNRVDY 0260-2288 Google Scholar
J. Garciaet al.,
“Three-dimensional mapping and range measurement by means of projected speckle patterns,”
Appl. Opt., 47
(16), 3032
–3040
(2008). http://dx.doi.org/10.1364/AO.47.003032 APOPAI 0003-6935 Google Scholar
Y.-S. ChenB.-T. Chen,
“Measuring of a three-dimensional surface by use of a spatial distance computation,”
Appl. Opt., 42
(11), 1958
–1972
(2003). http://dx.doi.org/10.1364/AO.42.001958 APOPAI 0003-6935 Google Scholar
M. Schafferet al.,
“High-speed three-dimensional shape measurements of objects with laser speckles and acousto-optical deflection,”
Opt. Lett., 36
(16), 3097
–3099
(2011). http://dx.doi.org/10.1364/OL.36.003097 OPLEDP 0146-9592 Google Scholar
D. ScharsteinR. Szeliski,
“A taxonomy and evaluation of dense two-frame stereo correspondence algorithms,”
Int. J. Comput. Vision, 47
(1–3), 7
–42
(2002). http://dx.doi.org/10.1023/A:1014573219977 IJCVEQ 0920-5691 Google Scholar
G. Wanget al.,
“Depth estimation for speckle projection system using progressive reliable points growing matching,”
Appl. Opt., 52
(9), 516
–524
(2013). http://dx.doi.org/10.1364/AO.52.000516 APOPAI 0003-6935 Google Scholar
C. Shiet al.,
“Stereo matching using local plane fitting in confidence-based support window,”
IEICE Trans. Inf. Syst., E95-D
(2), 699
–702
(2012). http://dx.doi.org/10.1587/transinf.E95.D.699 ITISEF 0916-8532 Google Scholar
S. K. Nayaret al.,
“Fast separation of direct and global components of a scene using high frequency illumination,”
ACM Trans. Graph., 25
(3), 935
–944
(2006). http://dx.doi.org/10.1145/1141911 ATGRDF 0730-0301 Google Scholar
R. ZabihJ. Woodfill,
“Non-parametric local transforms for computing visual correspondence,”
in European Conf. Computer Vision,
151
–158
(1994). Google Scholar
A. GeigerM. RoserR. Urtasun,
“Efficient large-scale stereo matching,”
in Computer Vision-ACCV,
25
–38
(2010). Google Scholar
C. Shiet al.,
“An interleaving updating framework of disparity and confidence map for stereo matching,”
IEICE Trans. Inf. Syst., E95-D
(5), 1552
–1555
(2012). http://dx.doi.org/10.1587/transinf.E95.D.1552 ITISEF 0916-8532 Google Scholar
M. GongY.-H. Yang,
“Fast unambiguous stereo matching using reliability-based dynamic programming,”
IEEE Trans. Pattern Anal. Mach. Intell., 27
(6), 998
–1003
(2005). http://dx.doi.org/10.1109/TPAMI.2005.120 ITPIDJ 0162-8828 Google Scholar
N. SabaterA. AlmansaJ. M. Morel,
“Meaningful matches in stereovision,”
IEEE Trans. Pattern Anal. Mach. Intell., 34
(5), 930
–942
(2012). http://dx.doi.org/10.1109/TPAMI.2011.207 ITPIDJ 0162-8828 Google Scholar
X. HuP. Mordohai,
“A quantitative evaluation of confidence measures for stereo vision,”
IEEE Trans. Pattern Anal. Mach. Intell., 34
(11), 2121
–2133
(2012). http://dx.doi.org/10.1109/TPAMI.2011.283 ITPIDJ 0162-8828 Google Scholar
I. HallerS. Nedevschi,
“Design of interpolation functions for subpixel-accuracy stereo-vision systems,”
IEEE Trans. Image Process., 21
(2), 889
–898
(2012). http://dx.doi.org/10.1109/TIP.2011.2163163 IIPRE4 1057-7149 Google Scholar
K. KhoshelhamS. O. Elberink,
“Accuracy and resolution of kinect depth data for indoor mapping applications,”
Sensors, 12
(20), 1437
–1454
(2012). http://dx.doi.org/10.3390/s120201437 SNSRES 0746-9462 Google Scholar
BiographyXuanwu Yin received his BS degree from Tsinghua University, Beijing, China, in 2011. He is currently working toward his PhD degree in electronic engineering with Tsinghua University, Beijing, China. His research interests include passive/active depth sensing technique, 3-D reconstruction, and computational imaging. Guijin Wang received his BS and PhD degrees (with honor) from Tsinghua University, China, in 1998 and 2003, respectively, all in electronic engineering. From 2003 to 2006, he was a researcher at Sony Information Technologies Laboratories. Since October 2006, he has been with the Department of Electronic Engineering, Tsinghua University, China, as an associate professor. His research interests focus on wireless multimedia, depth sensing, pose recognition, intelligent human-machine UI, intelligent surveillance, industry inspection, and online learning. Chenbo Shi received his BS and PhD degrees from the Department of Electronic Engineering, Tsinghua University, China, in 2005 and 2012, respectively. From 2008 to 2012, he published over 10 international journal and conference papers. He is the reviewer for several international journals and conferences. Now, he is a postdoctoral researcher in Tsinghua University. His research interests are focused on image stitching, stereo matching, matting, object detection, and tracking. Qingmin Liao received his PhD degree in signal processing and telecommunications from the University of Rennes, France, in 1994. Currently, he is a professor and head of the Laboratory of Visual Information Processing at Graduate School at Shenzhen, Tsinghua University, Shenzhen, China, where he became interested in image/video analysis, computer vision and its applications. |